Introduction to Git for Data Science
Version control allows you to keep track of what you did when, undo any changes you have decided you don't want, and collaborate at scale with other people.
Stregnths:
Nothing that is saved to Git is ever lost, so you can always go back to see which results were generated by which versions of your programs.
Git automatically notifies you when your work conflicts with someone else's, so it's harder (but not impossible) to accidentally overwrite work.
Git can synchronize work done by different people on different machines, so it scales as your team does.
Basic Workflow
- Where does Git store information?
Each of your Git projects has two parts: the files and directories that you create and edit directly, and the extra information that Git records about the project's history. The combination of these two things is called a repository.
Git stores all of its extra information in a directory called.gitlocated in the root directory of the repository. Git expects this information to be laid out in a very precise way, so you should never edit or delete anything in.git. - Check the state of a repository (
git status)
Run the commandgit status, which displays a list of the files that have been modified since the last time changes were saved.- Remark.Use
lsto list the files in your current working directory.
- Remark.Use
- How to tell what I have changed? (
git diff filename)
Git has a staging area in which it stores files with changes you want to save that haven't been saved yet. Putting files in the staging area is like putting things in a box, while committing those changes is like putting that box in the mail: you can add more things to the box or take things out as often as you want, but once you put it in the mail, you can't make further changes.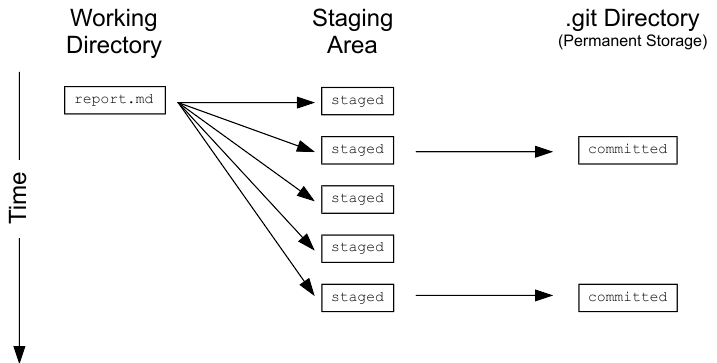
git statusshows you which files are in this staging area, and which files have changes that haven't yet been put there. In order to compare the file as it currently is to what you last saved, you can usegit diff filename.
Remark.git diffwithout any filenames will show you all the changes in your repository, whilegit diff directorywill show you the changes to the files in some directory.
What is in a diff? A diff is a formatted display of the differences between two sets of files. Git displays diffs like this: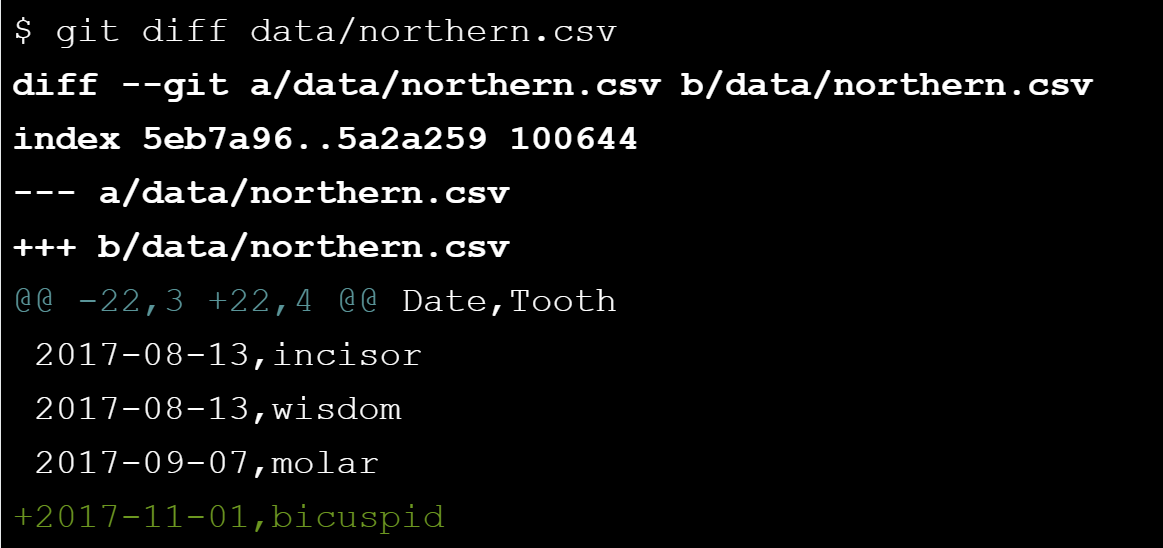
- The command used to produce the output (in this case,
diff --git). In it,aandbare placeholders meaning "the first version" and "the second version". - An index line showing keys into Git's internal database of changes. We will explore these in the next chapter.
--- a/data/nothern.csvand+++ b/, which indicate that lines being removed are prefixed withdata/nothern.csv-, while lines being added are prefixed with+.- A line starting with
@@that tells where the changes are being made. The pairs of numbers arestart line,number of lines changed. Here, the diff output shows that 3 lines from line 22 are being removed and replaced with 4 lines. - A line-by-line listing of the changes with
-showing deletions and+showing additions. (We have also configured Git to show deletions in red and additions in green.) Lines that haven't changed are sometimes shown before and after the ones that have in order to give context; when they appear, they don't have either+or-in front of them. In this example we see that only 1 line was added and the 3 first lines are to give context.
- The command used to produce the output (in this case,
- What's the first step in saving changes? (
git add filename)
You commit changes to a Git repository in two steps:
1.Add one or more files to the staging area
2. Commit everything in the staging area
To add a file to the staging area, usegit add filename. - How can I tell what's going to be committed? (
git diff -r HEAD)
To compare the state of your files (the ones already committed) with those in the staging area, you can usegit diff -r HEAD. The-rflag means "compare to a particular revision", andHEADis a shortcut meaning "the most recent commit".You can restrict the results to a single file or directory using
git diff -r HEAD path/to/file How do I commit changes? (
git commit)To save the changes in the staging area, you use the command
git commit. It always saves everything that is in the staging area as one unit: as you will see later, when you want to undo changes to a project, you undo all of a commit or none of it.When you commit changes, Git requires you to enter a log message. This serves the same purpose as a comment in a program: it tells the next person to examine the repository why you made a change.
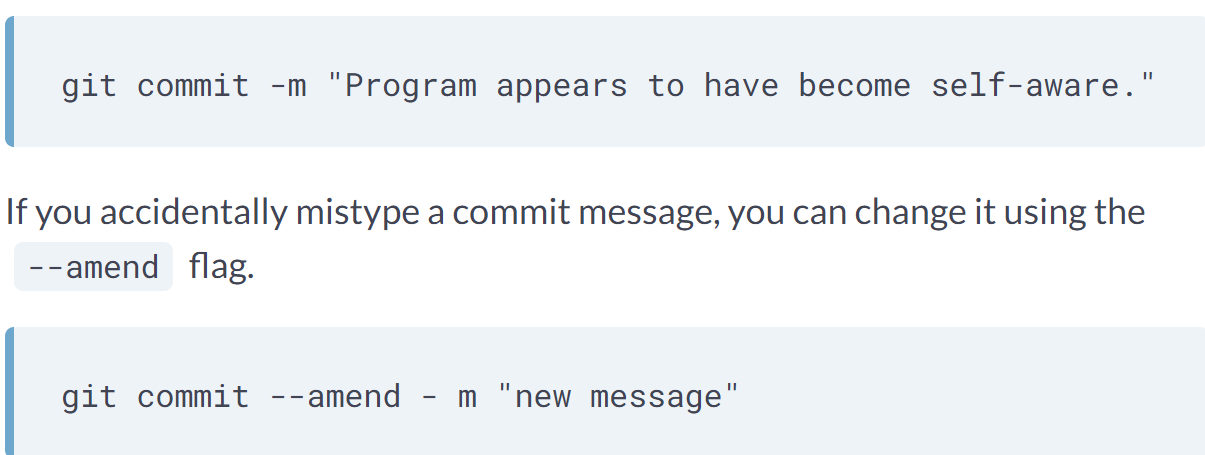
Writing a better log message.
git commit -m "message"is good enough for very small changes, but your collaborators will appreciate more information. If you rungit commitwithout-m "message", Git launches a text editor with a template like this (The lines starting with#are comments, and won't be saved):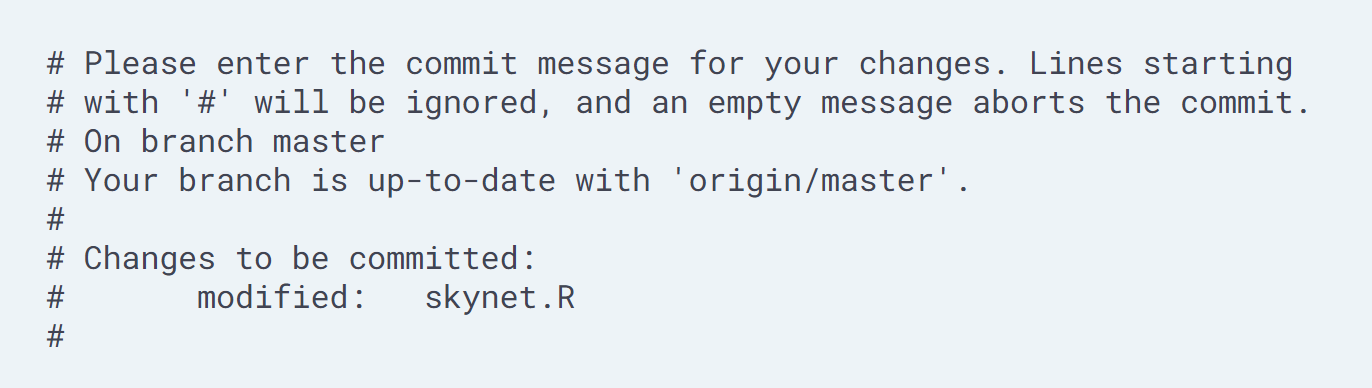
How can I view a repository's history or a specific file's history? (
git log)Repository's history. The command
git logis used to view the log of the project's history. Log entries are shown most recent first, and look like this: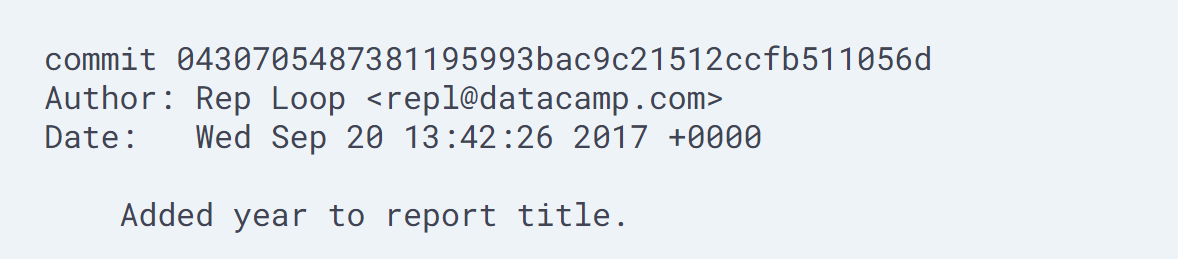
Specific file's history. You can do this using
git log path, wherepathis the path to a specific file or directory.Remark.
Passing
-then a number restricts the output to that many commits. For example,git log -3 report.txtshows you the last three commits involvingreport.txt.The log for a file shows changes made to that file; the log for a directory shows when files were added or deleted in that directory, rather than when the contents of the directory's files were changed
Interlude: how can I edit a file?

Repositories
- How does Git store information?
Git uses a three-level structure for this.- A commit contains metadata such as the author, the commit message, and the time the commit happened.
- Each commit also has a tree, which tracks the names and locations in the repository when that commit happened.
- For each of the files listed in the tree, there is a blob. This contains a compressed snapshot of the contents of the file when the commit happened. (Blob is short for binary large object, which is a SQL database term for "may contain data of any kind".)
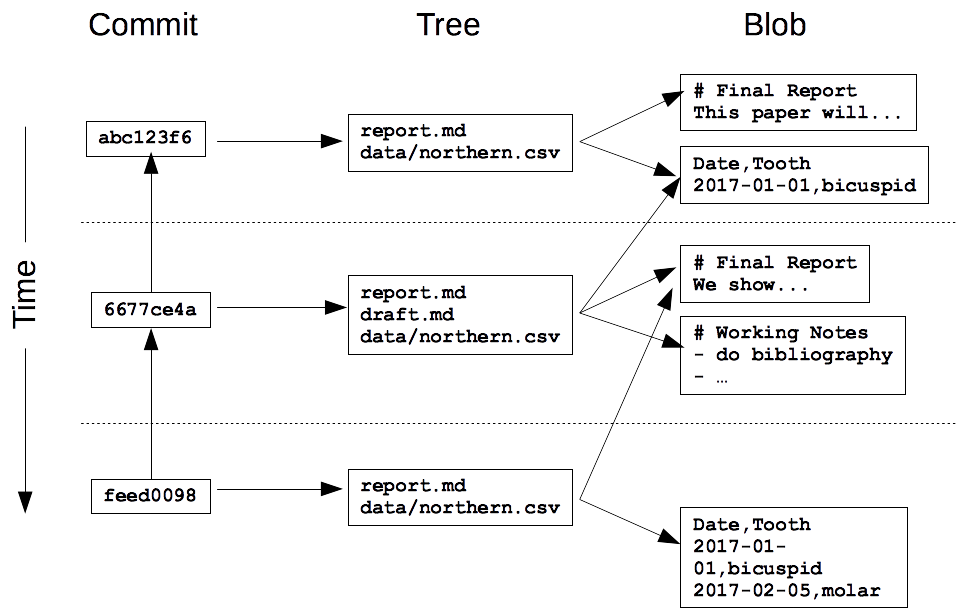
- Remark. Reusing blobs between commits help make common operations fast and minimizes storage space.
- What is a hash?
Every commit to a repository has a unique identifier called a hash (since it is generated by running the changes through a pseudo-random number generator called a hash function ).
Hashes are what enable Git to share data efficiently between repositories. If two files are the same, their hashes are guaranteed to be the same. Similarly, if two commits contain the same files and have the same ancestors, their hashes will be the same as well. Git can therefore tell what information needs to be saved where by comparing hashes rather than comparing entire files. - How can I view a specific commit? (
git show)
To view the details of a specific commit, you use the commandgit showwith the first few characters of the commit's hash. For example, the commandgit show 0da2f7produces this: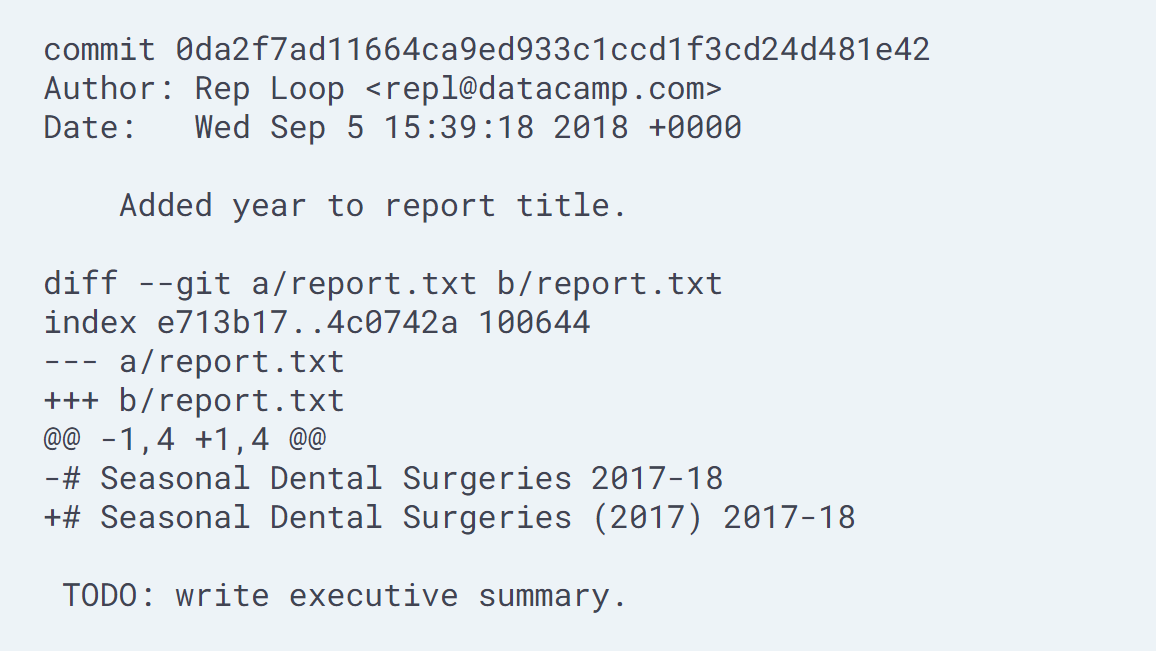
- Remark. The first part is the same as the log entry shown by
git log. The second part shows the changes; as withgit diff, lines that the change removed are prefixed with-, while lines that it added are prefixed with+
- Remark. The first part is the same as the log entry shown by
- Identify a commit using the equivalent of a relative path. (
HEAD~1)
The special labelHEADalways refers to the most recent commit. The labelHEAD~1then refers to the commit before it, whileHEAD~2refers to the commit before that, and so on.- Ex. show the commit made just before the most recent one.
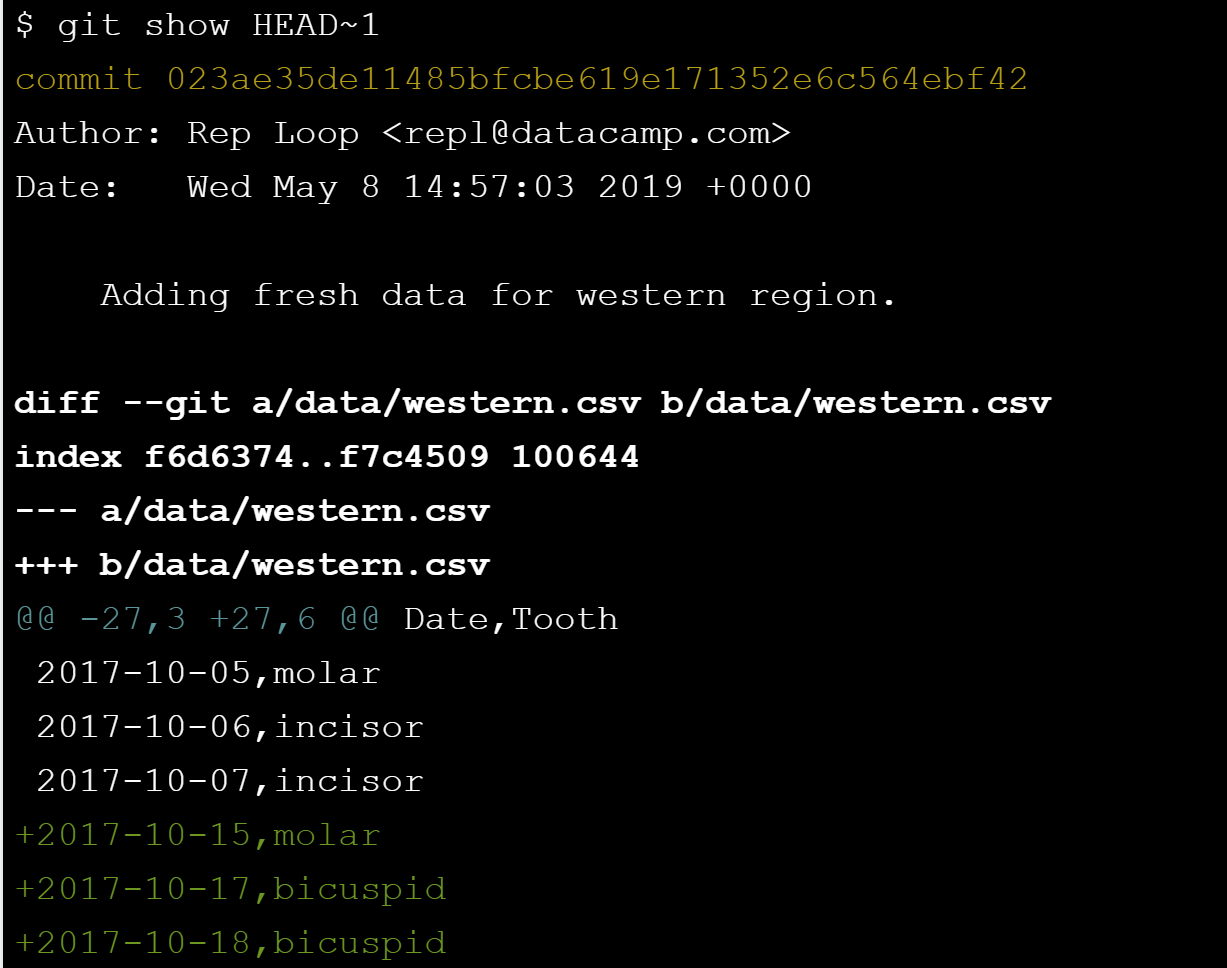
- Ex. show the commit made just before the most recent one.
- How can I see who changed what in a file? (
git annotate file)git logdisplays the overall history of a project or file, but Git can give even more information: the commandgit annotate fileshows who made the last change to each line of a file and when. For example, the first three lines of output fromgit annotate report.txtlook something like this:

- How can I see what changed between two commits? (
git diff ID1..ID2)git showwith a commit ID shows the changes made in a particular commit. To see the changes between two commits, you can usegit diff ID1..ID2, whereID1andID2identify the two commits you're interested in, and the connector..is a pair of dots. For example,git diff abc123..def456shows the differences between the commitsabc123anddef456, whilegit diff HEAD~1..HEAD~3shows the differences between the state of the repository one commit in the past and its state three commits in the past. - How do I add new files?
Git does not track files by default. Instead, it waits until you have usedgit addat least once before it starts paying attention to a file.- Ex.
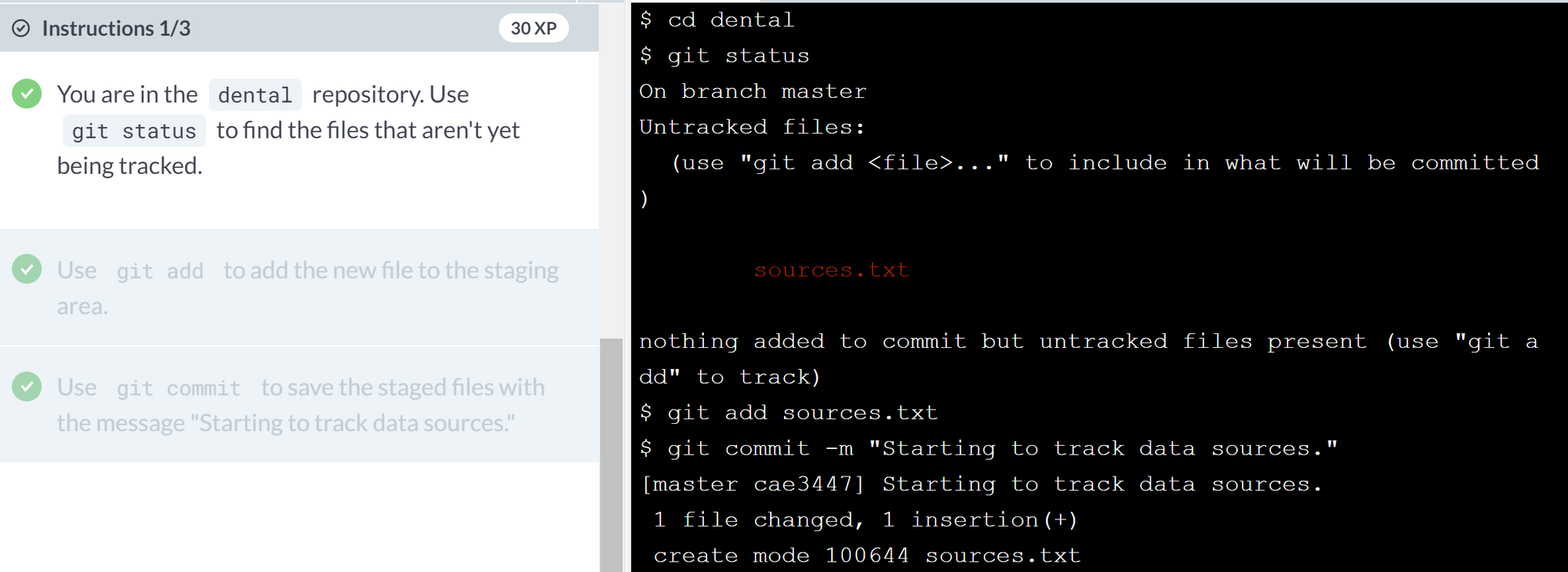
- Ex.
- How do I tell Git to ignore certain files? (
.gitignore)
You can tell Git to stop paying attention to files you don't care about by creating a file in the root directory of your repository called.gitignoreand storing a list of wildcard patterns that specify the files you don't want Git to pay attention to. For example, if.gitignorecontains:build*.mplthen Git will ignore any file or directory called
build(and, if it's a directory, anything in it), as well as any file whose name ends in.mpl. How can I remove unwanted files? (
git clean)Git can help you clean up files that you have told it you don't want. The command
git clean -nwill show you a list of files that are in the repository, but whose history Git is not currently tracking. A similar commandgit clean -fwill then delete those files.Use this command carefully:
git cleanonly works on untracked files, so by definition, their history has not been saved. If you delete them withgit clean -f, they're gone for good.Git configuration
To see what the settings are, you can use the command
git config --listwith one of three additional options:--system: settings for every user on this computer.--global: settings for every one of your projects.--local: settings for one specific project.- Remark. Each level overrides the one above it; the inner the level the more the priority
- Changing the configuration.
To change a configuration value for all of your projects on a particular computer, run the command:git config --global setting.name setting.valuewith the setting's name and value in the appropriate places. The keys that identify your name and email address areuser.nameanduser.emailrespectively.- Ex. Change the email address (
user.email) configured for the current user for all projects torep.loop@datacamp.com.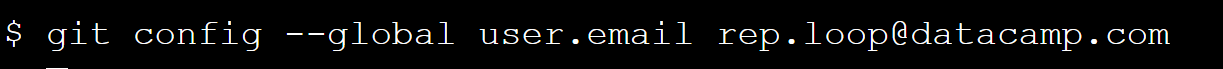
- Ex. Change the email address (
Undo
- Commit changes selectively. (
git reset HEAD)
You don't have to put all of the changes you have made recently into the staging area at once. For example, suppose you are adding a feature toanalysis.Rand spot a bug incleanup.R. After you have fixed it, you want to save your work. Since the changes tocleanup.Raren't directly related to the work you're doing inanalysis.R, you should save your work in two separate commits.- The syntax for staging a single file is
git add path/to/file. - If you make a mistake and accidentally stage a file you shouldn't have, you can unstage the additions with
git reset HEADand try again.
- The syntax for staging a single file is
- Re-staging files
It is common to usegit addperiodically to save the most recent changes to a file to the staging area. - Undoing changes to unstaged files (
git checkout)
Suppose you have made changes to a file, then decide you want to undo them. Your text editor may be able to do this, but a more reliable way is to let Git do the work. The command:git checkout -- filenamewill discard the changes that have not yet been staged. (The double dash
--must be there to separate thegit checkoutcommand from the names of the file or files you want to recover.)Use this command carefully: once you discard changes in this way, they are gone forever.
Ex.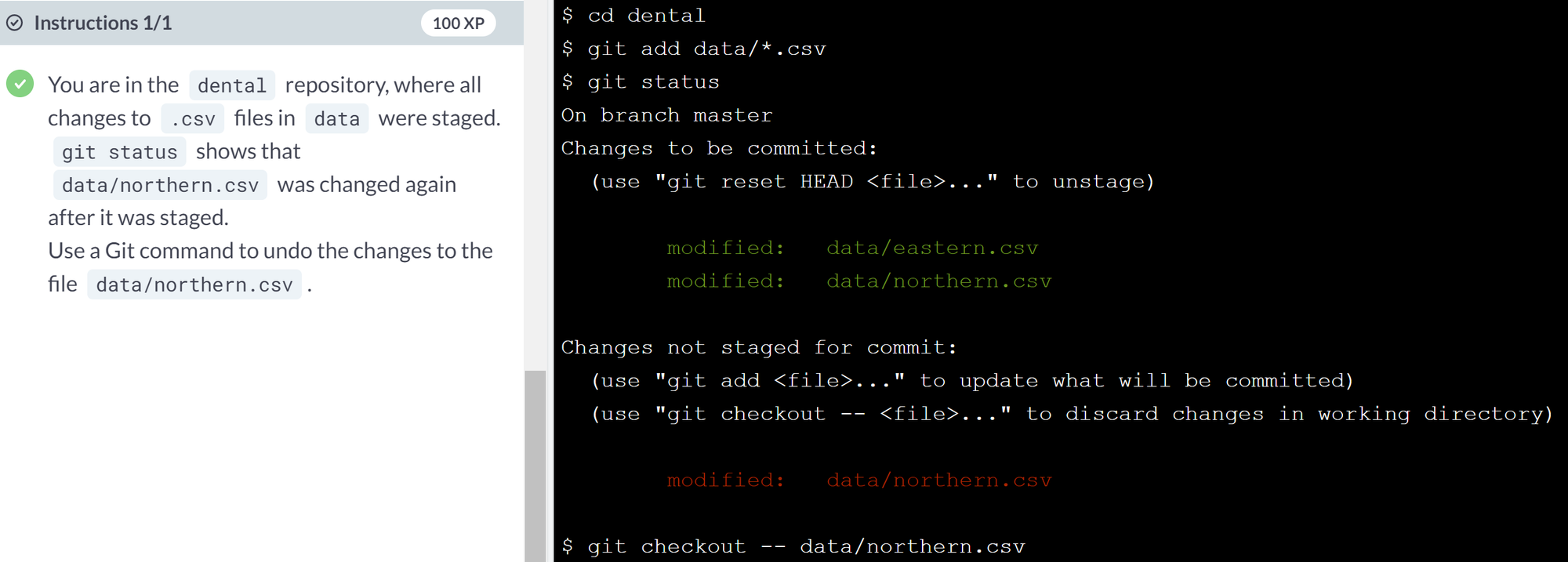
How do I undo changes to staged files?
At the start of this chapter you saw that
git resetwill unstage files that you previously staged usinggit add. By combininggit resetwithgit checkout, you can undo changes to a file that you staged changes to. The syntax is as follows.git reset HEAD path/to/filegit checkout -- path/to/file- How do I restore an old version of a file?
git checkoutcan also be used to go back even further into a file's history and restore versions of that file from a commit.- The syntax for restoring an old version takes two arguments: the hash that identifies the version you want to restore, and the name of the file.
For example, if
git logshows this:commit ab8883e8a6bfa873d44616a0f356125dbaccd9ea Author: Author: Rep Loop Date: Thu Oct 19 09:37:48 2017 -0400 Adding graph to show latest quarterly results. commit 2242bd761bbeafb9fc82e33aa5dad966adfe5409 Author: Author: Rep Loop Date: Thu Oct 16 09:17:37 2017 -0400 Modifying the bibliography format.then
git checkout 2242bd report.txtwould replace the current version ofreport.txtwith the version that was committed on October 16. Notice that this is the same syntax that you used to undo the unstaged changes, except--has been replaced by a hash. Remark. Restoring a file doesn't erase any of the repository's history. Instead, the act of restoring the file is saved as another commit, because you might later want to undo your undoing.
- The syntax for restoring an old version takes two arguments: the hash that identifies the version you want to restore, and the name of the file.
- How can I undo all of the changes I have made?
You will sometimes want to undo changes to many files.One way to do this is to give
git reseta directory. For example,git reset HEAD datawill unstage any files from thedatadirectory. Even better, if you don't provide any files or directories, it will unstage everything. Even even better,HEADis the default commit to unstage, so you can simply writegit resetto unstage everything.Similarly
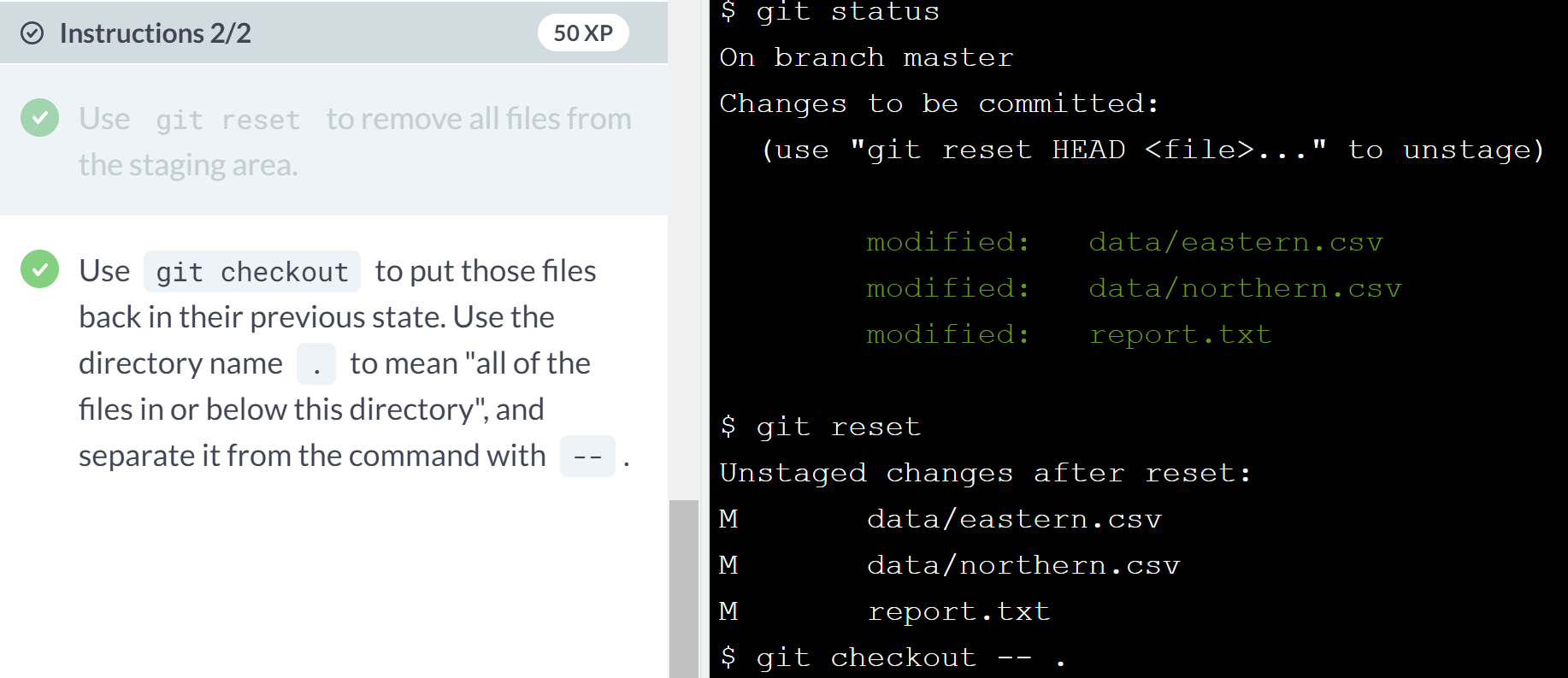
git checkout -- datawill then restore the files in thedatadirectory to their previous state. You can't leave the file argument completely blank, but recall that you can refer to the current directory as.. Sogit checkout -- .will revert all files in the current directory.Ex. We want to remove all files form stagin area and putting them back in their previous state. After all this they "exist" but are unstaged.
Working with branches
Branching is one of Git's most powerful features, since it allows you to work on several things at once without tripping over yourself.
- What is a branch?
Branches allow you to have multiple versions of your work, and lets you track each version systematically.
Each branch is like a parallel universe: changes you make in one branch do not affect other branches (until you merge them back together).
- What branches my repository has? (
git branch)
By default, every Git repository has a branch calledmaster(which is why you have been seeing that word in Git's output in previous lessons). To list all of the branches in a repository, you can run the commandgit branch. The branch you are currently in will be shown with a*beside its name.
- How can I view the differences between branches? (
git diff branch-1..branch-2)
Branches and revisions are closely connected, and commands that work on the latter usually work on the former. For example, just asgit diff revision-1..revision-2shows the difference between two versions of a repository,git diff branch-1..branch-2shows the difference between two branches.
- How can I switch from one branch to another?
You can also usegit checkoutwith the name of a branch to switch to that branch.- Ex.
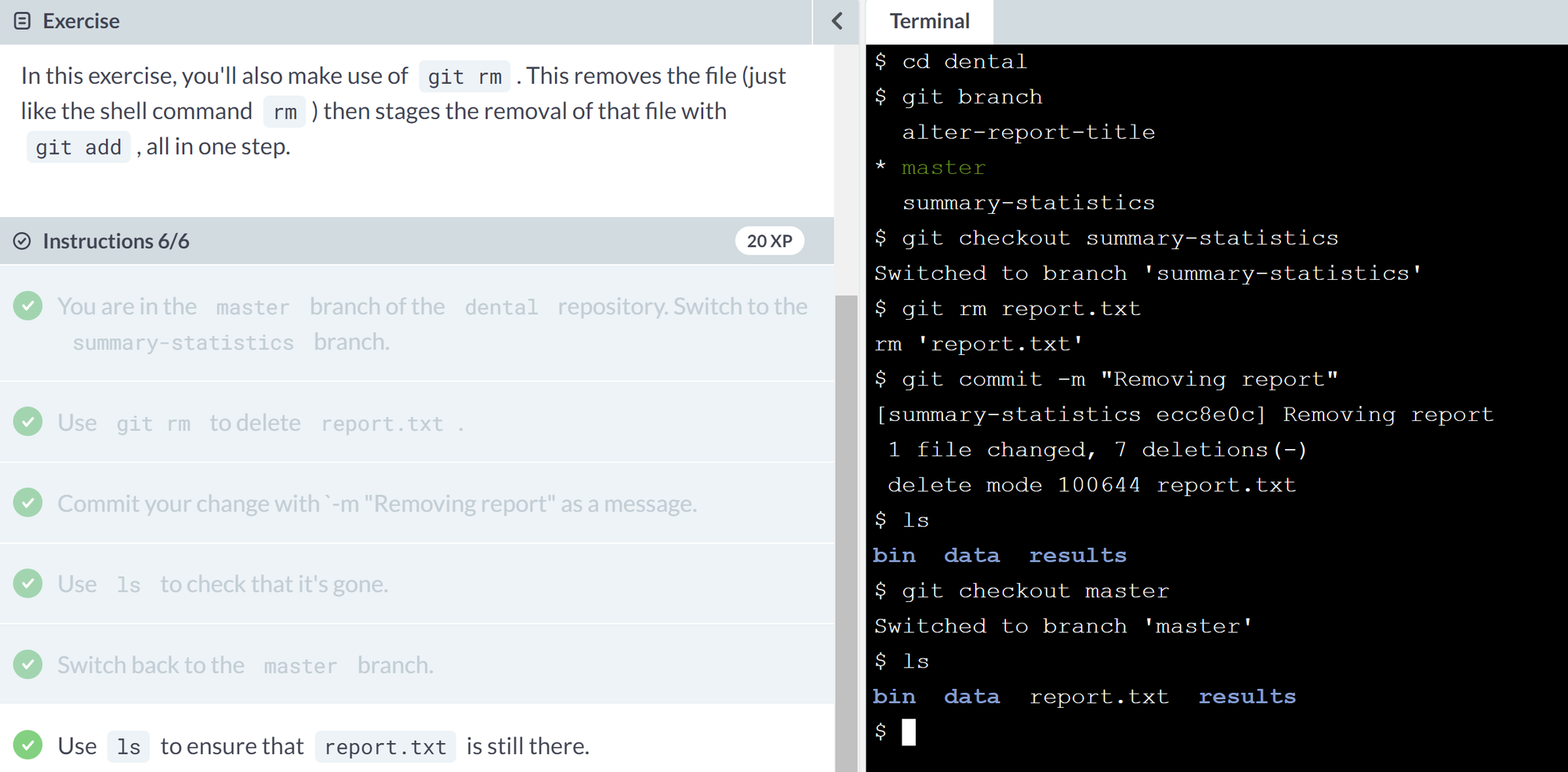
- Ex.
- How can I create a branch? (
git checkout -b branch-name)
You might expect that you would usegit branchto create a branch, and indeed this is possible. However, the most common thing you want to do is to create a branch then switch to that branch.
In the previous exercise, you usedgit checkout branch-nameto switch to a branch. To create a branch then switch to it in one step, you add a-bflag, callinggit checkout -b branch-name,The contents of the new branch are initially identical to the contents of the original. Once you start making changes, they only affect the new branch.
How can I merge two branches? (
git merge)Branching lets you create parallel universes; merging is how you bring them back together. When you merge one branch (call it the source) into another (call it the destination), Git incorporates the changes made to the source branch into the destination branch. If those changes don't overlap, the result is a new commit in the destination branch that includes everything from the source branch. (The next exercises describes what happens if there are conflicts.)
To merge two branches, you run
git merge source destination. Git automatically opens an editor so that you can write a log message for the merge; you can either keep its default message or fill in something more informative.
What are conflicts?
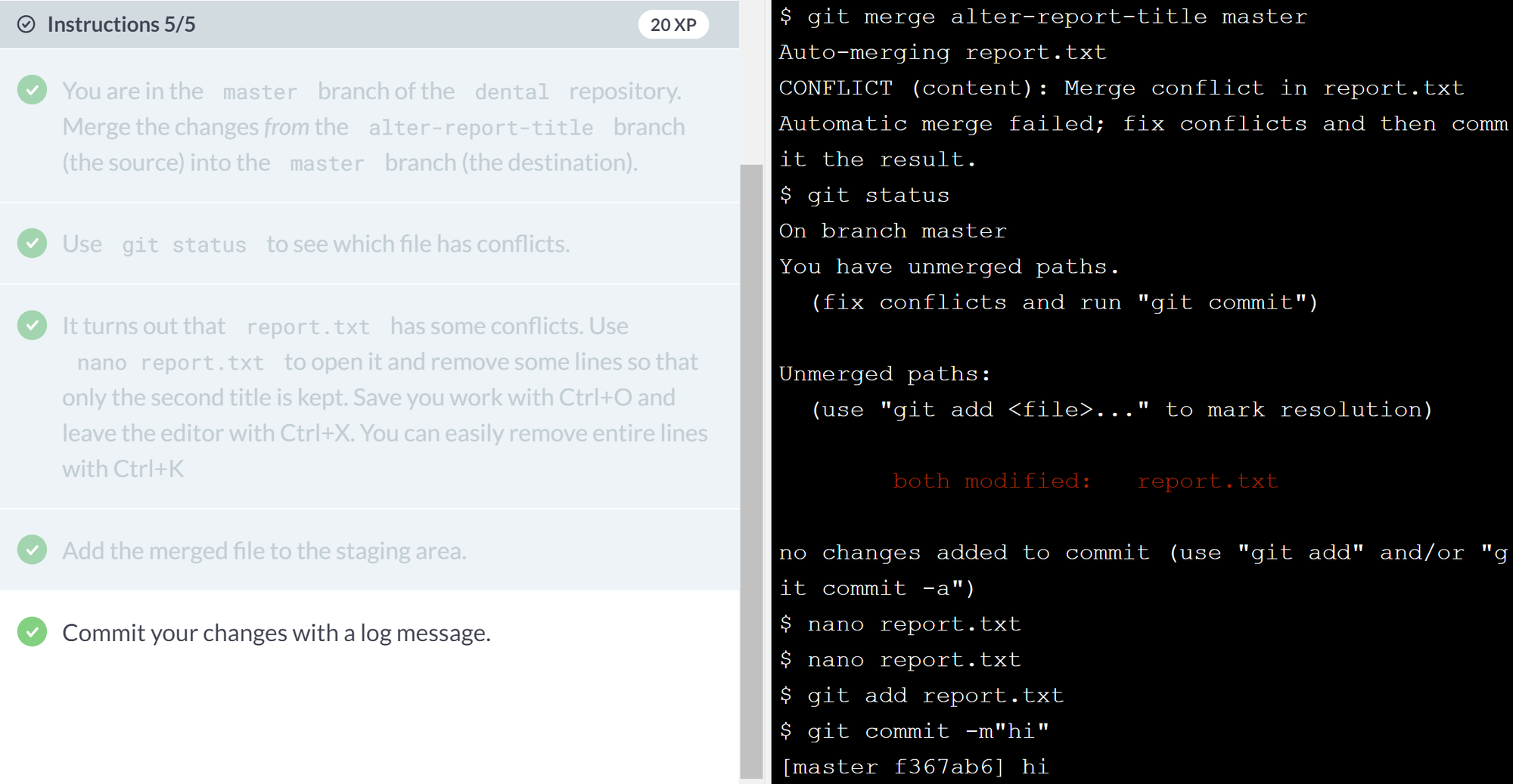
Sometimes the changes in two branches will conflict with each other: for example, bug fixes might touch the same lines of code, or analyses in two different branches may both append new (and different) records to a summary data file. In this case, Git relies on you to reconcile the conflicting changes.How can I merge two branches with conflicts?
When there is a conflict during a merge, Git tells you that there's a problem, and running
git statusafter the merge reminds you which files have conflicts that you need to resolve by printingboth modified:beside the files' names.Inside the file, Git leaves markers that look like this to tell you where the conflicts occurred:
<<<<<<< destination-branch-name...changes from the destination branch...=======...changes from the source branch...>>>>>>> source-branch-name(In many cases, the destination branch name will be
HEAD, because you will be merging into the current branch.) To resolve the conflict, edit the file to remove the markers and make whatever other changes are needed to reconcile the changes, then commit those changes.Ex.
Collaborating
This chapter shows Git's other greatest feature: how you can share changes between repositories to collaborate at scale.
- How can I create a brand new repository? (
git init project-name)
So far, you have been working with repositories that we created. If you want to create a repository for a new project, you can simply saygit init project-name, where "project-name" is the name you want the new repository's root directory to have.- Remark.
- One thing you should not do is create one Git repository inside another. While Git does allow this, updating nested repositories becomes very complicated very quickly, since you need to tell Git which of the two
.gitdirectories the update is to be stored in. - You'll often want to turn an existing folder into a Git repo as well.
- One thing you should not do is create one Git repository inside another. While Git does allow this, updating nested repositories becomes very complicated very quickly, since you need to tell Git which of the two
- Remark.
- Turning an existing project into a Git repository
You will often want to convert existing projects into repositories. Doing so is simple: just rungit initin the project's root directory, or
git init /path/to/projectfrom anywhere else on your computer.
Ex.
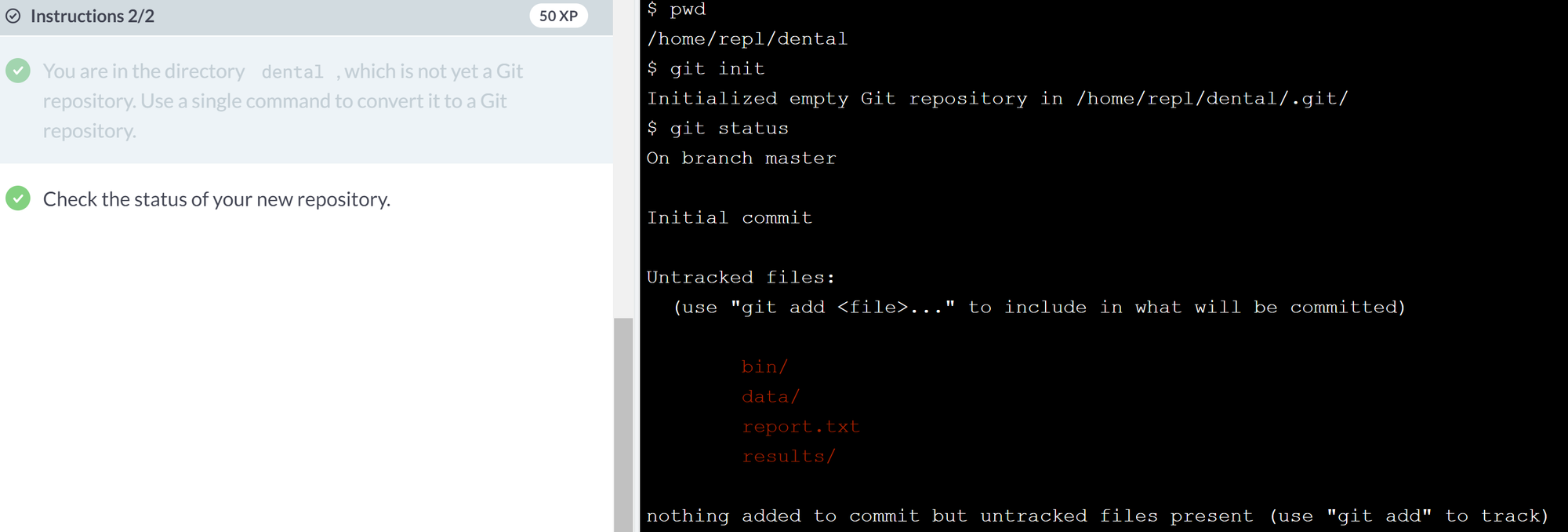
Remark. After initializing the folder into a repository, Git immediately notices that there are a bunch of changes that can be staged (and afterwards, commited)
How can I create a copy of an existing repository? (
git clone URL)
Sometimes you will join a project that is already running, inherit a project from someone else, or continue working on one of your own projects on a new machine. In each case, you will clone an existing repository instead of creating a new one. Cloning a repository does exactly what the name suggests: it creates a copy of an existing repository (including all of its history) in a new directory.To clone a repository, use the command
git clone URL, whereURLidentifies the repository you want to clone. This will normally be something likehttps://github.com/datacamp/project.git
When you clone a repository, Git uses the name of the existing repository as the name of the clone's root directory: for example,git clone /existing/projectwill create a new directory called
project. If you want to call the clone something else, add the directory name you want to the command:git clone /existing/project newprojectnameHow can I find out where a cloned repository originated? (
git remote)
When you clone a repository, Git remembers where the original repository was. It does this by storing a remote in the new repository's configuration.If you use an online git repository hosting service like GitHub or Bitbucket, a common task would be that you clone a repository from that site to work locally on your computer. Then the copy on the website is the remote.
If you are in a repository, you can list the names of its remotes using
git remote.If you want more information, you can use
git remote -v(for "verbose"), which shows the remote's URLs.Remark. When you clone a repository, Git automatically creates a remote called origin that points to the original repository.
How can I define remotes?
You can add more remotes using:
git remote add remote-name URLand remove existing ones using:
git remote rm remote-name
- How can I pull in changes from a remote repository? (
git pull remote branch)
Git keeps track of remote repositories so that you can pull changes from those repositories and push changes to them.Recall that the remote repository is often a repository in an online hosting service like GitHub. A typical workflow is that you pull in your collaborators' work from the remote repository so you have the latest version of everything, do some work yourself, then push your work back to the remote so that your collaborators have access to it.
Pulling changes is straightforward: the command
git pull remote branchgets everything inbranchin the remote repository identified byremoteand merges it into the current branch of your local repository. For example, if you are in thequarterly-reportbranch of your local repository, the command:git pull thunk latest-analysiswould get changes from
latest-analysisbranch in the repository associated with the remote calledthunkand merge them into yourquarterly-reportbranch.- What happens if I try to pull when I have unsaved changes?
Git stops you from pulling in changes from a remote repository when doing so might overwrite things you have done locally. The fix is simple: either commit your local changes or revert them (using checkout), and then try to pull again.
- What happens if I try to pull when I have unsaved changes?
- How can I push my changes to a remote repository? (
git push)
The complement ofgit pullisgit push, which pushes the changes you have made locally into a remote repository. The most common way to use it is:git push remote-name branch-namewhich pushes the contents of your branch
branch-nameinto a branch with the same name in the remote repository associated withremote-name. It's possible to use different branch names at your end and the remote's end, but doing this quickly becomes confusing: it's almost always better to use the same names for branches across repositories.What happens if my push conflicts with someone else's work?
Overwriting your own work by accident is bad; overwriting someone else's is worse.
To prevent this happening, Git does not allow you to push changes to a remote repository unless you have merged the contents of the remote repository into your own work.



