Introduction to Shell for Data Science
An OS controls the computer's processor, hard drive, and network connection, but its most important job is to run other programs.
Humans need an interface to interact with the OS. The most common one these days is a graphical file explorer, which translates clicks and double-clicks into commands to open files and run programs. Before computers had graphical displays, though, people typed instructions into a program called a command-line shell. Each time a command is entered, the shell runs some other programs, prints their output in human-readable form, and then displays a prompt to signal that it's ready to accept the next command.
Remark. Typing commands instead of clicking and dragging may seem clumsy at first, but as you will see, once you start spelling out what you want the computer to do, you can combine old commands to create new ones and automate repetitive operations with just a few keystrokes.
Manipulating files and directories
We will view commands that let you move things around in the filesystem
- Where am I? (
pwd)
The filesystem manages files and directories (or folders). Each is identified by an absolute path that shows how to reach it from the filesystem's root directory:/home/replis the directoryreplin the directoryhome, while/home/repl/course.txtis a filecourse.txtin that directory, and/on its own is the root directory.To find out where you are in the filesystem, run the command
pwd(short for "print working directory"). This prints the absolute path of your current working directory, which is where the shell runs commands and looks for files by default. How can I identify files and directories? (
ls)pwdtells you where you are. To find out what's there, typels(which is short for "listing") and press the enter key. On its own,lslists the contents of your current directory (the one displayed bypwd). If you add the names of some files,lswill list them, and if you add the names of directories, it will list their contents.Absolute and relative path
An absolute path is like a latitude and longitude: it has the same value no matter where you are. A relative path, on the other hand, specifies a location starting from where you are: it's like saying "20 kilometers north".
For example, if you are in the directory
/home/repl, the relative pathseasonalspecifies the same directory as/home/repl/seasonal, whileseasonal/winter.csvspecifies the same file as/home/repl/seasonal/winter.csv. The shell decides if a path is absolute or relative by looking at its first character: if it begins with/, it is absolute, and if it doesn't, it is relative.
How can I move to another directory? (
cd)Just as you can move around in a file browser by double-clicking on folders, you can move around in the filesystem using the command
cd(which stands for "change directory").If you type
cd seasonaland then typepwd, the shell will tell you that you are now in/home/repl/seasonal. If you then runlson its own, it shows you the contents of/home/repl/seasonal, because that's where you are. If you want to get back to your home directory/home/repl, you can use the commandcd /home/repl.How can I move up a directory? (
..) , (.) and (~)
The parent of a directory is the directory above it. For example,/homeis the parent of/home/repl, and/home/replis the parent of/home/repl/seasonal. You can always give the absolute path of your parent directory to commands likecdandls. More often, though, you will take advantage of the fact that the special path..(two dots with no spaces) means "the directory above the one I'm currently in". If you are in/home/repl/seasonal, thencd ..moves you up to/home/repl.
A single dot on its own,., always means "the current directory", solson its own andls .do the same thing, whilecd .has no effect.
One final special path is~(the tilde character), which means "your home directory", such as/home/repl. No matter where you are,ls ~will always list the contents of your home directory, andcd ~will always take you home.
How can I copy files? (
cp)You will often want to copy files, move them into other directories to organize them, or rename them. One command to do this is
cp, which is short for "copy". Iforiginal.txtis an existing file, then:cp original.txt duplicate.txtcreates a copy of
original.txtcalledduplicate.txt. If there already was a file calledduplicate.txt, it is overwritten. If the last parameter tocpis an existing directory, then a command like:cp seasonal/autumn.csv seasonal/winter.csv backupcopies all of the files (autumn.csv and winter.csv) into that directory.
How can I move a file? (
mv)While
cpcopies a file,mvmoves it from one directory to another, just as if you had dragged it in a graphical file browser. It handles its parameters the same way ascp, so the command:mv autumn.csv winter.csv ..moves the files
autumn.csvandwinter.csvfrom the current working directory up one level to its parent directory (because..always refers to the directory above your current location).How can I rename a file? (
mv)mvcan also be used to rename files. If you run:mv course.txt old-course.txtthen the file
course.txtin the current working directory is "moved" to the fileold-course.txt. This is different from the way file browsers work, but is often handy.One warning: just like
cp,mvwill overwrite existing files. If, for example, you already have a file calledold-course.txt, then the command shown above will replace it with whatever is incourse.txt.How can I delete files? (
rm)We can copy files and move them around; to delete them, we use
rm, which stands for "remove". As withcpandmv, you can givermthe names of as many files as you'd like, so:rm thesis.txt backup/thesis-2017-08.txtremoves both
thesis.txtandbackup/thesis-2017-08.txtrmdoes exactly what its name says, and it does it right away: unlike graphical file browsers, the shell doesn't have a trash can, so when you type the command above, your thesis is gone for good.How can I create and delete directories? (
rmdir) and (mkdir)mvtreats directories the same way it treats files: if you are in your home directory and runmv seasonal by-season, for example,mvchanges the name of theseasonaldirectory toby-season. However,rmworks differently.If you try to
rma directory, the shell prints an error message telling you it can't do that, primarily to stop you from accidentally deleting an entire directory full of work. Instead, you can use a separate command calledrmdir. For added safety, it only works when the directory is empty, so you must delete the files in a directory before you delete the directory.Since a directory is not a file, you must use the command
mkdir directory_nameto create a new (empty) directory. Use this command to create a new directory calledyearlybelow your home directory.
/tmp
You will often create intermediate files when analyzing data. Rather than storing them in your home directory, you can put them in/tmp, which is where people and programs often keep files they only need briefly. (Note that/tmpis immediately below the root directory/, not below your home directory.) This wrap-up exercise will show you how to do that.
Manipulating data
This chapter will show you how to work with the data that's in the files. The tools we will look at are fairly simple, but are the model for everything that's more powerful.
- How can I view a file's contents? (
cat)
Before you rename or delete files, you may want to have a look at their contents. The simplest way to do this is withcat, which just prints the contents of files onto the screen. (Its name is short for "concatenate", meaning "to link things together", since it will print all the files whose names you give it, one after the other.) - How can I view a file's contents piece by piece? (
less)
You can usecatto print large files and then scroll through the output, but it is usually more convenient to page the output. The original command for doing this was calledmore, but it has been superseded by a more powerful command calledless. (This kind of naming is what passes for humor in the Unix world.) When youlessa file, one page is displayed at a time; you can press spacebar to page down or typeqto quit.If you give
lessthe names of several files, you can type:n(colon and a lower-case 'n') to move to the next file,:pto go back to the previous one, or:qto quit. How can I look at the start of a file? (
head)headprints the first few lines of a file (where "a few" means 10), so the command:head seasonal/summer.csvdisplays the fields and first 10 rows.
Tab completion
One of the shell's power tools is tab completion. If you start typing the name of a file and then press the tab key, the shell will do its best to auto-complete the path. For example, if you type
seaand press tab, it will fill in the directory nameseasonal/(with a trailing slash). If you then typeaand tab, it will complete the path asseasonal/autumn.csv.If the path is ambiguous, such as
seasonal/s, pressing tab a second time will display a list of possibilities. Typing another character or two to make your path more specific and then pressing tab will fill in the rest of the name.How can I control what commands do? (flags)
Shell lets you change
head's behavior by giving it a command-line flag (or just "flag" for short). If you run the command:head -n 3 seasonal/summer.csvheadwill only display the first three lines of the file. If you runhead -n 100, it will display the first 100 (assuming there are that many), and so on.A flag's name usually indicates its purpose (for example,
-nis meant to signal "number of lines"). Command flags don't have to be a-followed by a single letter, but it's a widely-used convention.How can I list everything below a directory?
In order to see everything underneath a directory, no matter how deeply nested it is, you can givelsthe flag-R(which means "recursive"); this shows every file and directory in the current level, then everything in each sub-directory, and so on.
To help you know what is what,lshas another flag-Fthat prints a/after the name of every directory and a*after the name of every runnable program.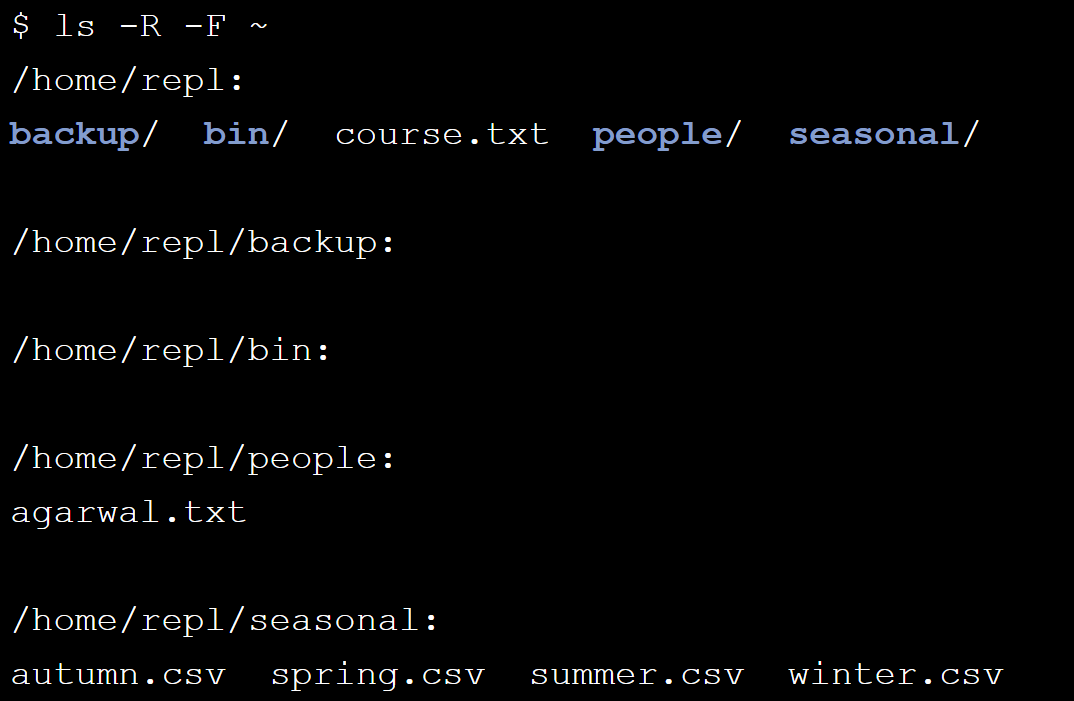
How can I get help for a command?
To find out what commands do, people used to use themancommand (short for "manual"). For example, the commandman headbrings up this information:
manautomatically invokesless, so you may need to press spacebar to page through the information and:qto quit.The one-line description under
NAMEtells you briefly what the command does, and the summary underSYNOPSISlists all the flags it understands. Anything that is optional is shown in square brackets[...], either/or alternatives are separated by|, and things that can be repeated are shown by..., sohead's manual page is telling you that you can either give a line count with-nor a byte count with-c, and that you can give it any number of filenames.How can I select columns from a file? (
cutwith -f -d)headandtaillet you select rows from a text file. If you want to select columns, you can use the commandcut. It has several options (useman cutto explore them), but the most common is something like:cut -f 2-5,8 -d , values.csvwhich means "select columns 2 through 5 and columns 8, using comma as the separator".
cutuses-f(meaning "fields") to specify columns and-d(meaning "delimiter") to specify the separator. You need to specify the latter because some files may use spaces, tabs, or colons to separate columns.What cut can't do?
cutis a simple-minded command. In particular, it doesn't understand quoted strings. If, for example, your file is:Name,Age"Johel,Ranjit",28"Sharma,Rupinder",26then:
cut -f 2 -d , everyone.csvwill produce:
AgeRanjit"Rupinder"
How can I repeat commands (
historyand!)historywill print a list of commands you have run recently. Each one is preceded by a serial number to make it easy to re-run particular commands: just type!55to re-run the 55th command in your history (if you have that many). You can also re-run a command by typing an exclamation mark followed by the command's name, such as!heador!cut, which will re-run the most recent use of that command.How can I select lines containing specific values? (
grep)grepselects lines according to what they contain. In its simplest form,greptakes a piece of text followed by one or more filenames and prints all of the lines in those files that contain that text. For example,grep bicuspid seasonal/winter.csvprints lines fromwinter.csvthat contain "bicuspid".grepcan search for patterns as well; we will explore those in the next course. What's more important right now is some ofgrep's more common flags:-c: print a count of matching lines rather than the lines themselves-h: do not print the names of files when searching multiple files-i: ignore case (e.g., treat "Regression" and "regression" as matches)-l: print the names of files that contain matches, not the matches-n: print line numbers for matching lines-v: invert the match, i.e., only show lines that don't match
Combining tools
The real power of the Unix shell lies not in the individual commands, but in how easily they can be combined to do new things. This chapter will show you how to use this power to select the data you want, and introduce commands for sorting values and removing duplicates.
- How can I store a command's output in a file? (
>)
you can use redirection to save any command's output anywhere you want. If you run this command:head -n 5 seasonal/summer.csv > top.csvnothing appears on the screen. Instead,
head's output is put in a new file calledtop.csv. You can take a look at that file's contents usingcat:cat top.csvThe greater-than sign
>tells the shell to redirecthead's output to a file. It isn't part of theheadcommand; instead, it works with every shell command that produces output. How can I use a command's output as an input?
Suppose you want to get lines from the middle of a file. More specifically, suppose you want to get lines 3-5 from one of our data files. You can start by usingheadto get the first 5 lines and redirect that to a file, and then usetailto select the last 3:
head -n 5 file.csv > new_file.csv
tail -n 3 new_file.csvWhat's a better way to combine commands? (
|)
The best way to so it is using a pipe .Instead of sending
head's output to a file, add a vertical bar and thetailcommand without a filename:head -n 5 seasonal/summer.csv | tail -n 3The pipe symbol tells the shell to use the output of the command on the left as the input to the command on the right.
How can I count the records in a file? (
wc)
The commandwc(short for "word count") prints the number of characters, words, and lines in a file. You can make it print only one of these using-c,-w, or-lrespectively.How can I specify many files at once? (
*)
The shell allows you to use wildcards to specify a list of files with a single expression. The most common wildcard is*, which means "match zero or more characters". Using it, we can shorten thecutcommand from this
cut -d , -f 1 seasonal/winter.csv seasonal/spring.csv seasonal/summer.csv seasonal/autumn.csv
to this:
cut -d , -f 1 seasonal/*What other wildcards can I use?

How can I sort lines of text?
As its name suggests,sortputs data in order. By default it does this in ascending alphabetical order, but the flags-nand-rcan be used to sort numerically and reverse the order of its output, while-btells it to ignore leading blanks and-ftells it to fold case (i.e., be case-insensitive). Pipelines often usegrepto get rid of unwanted records and thensortto put the remaining records in order.How can I remove duplicate lines? (
uniq)uniq, its job is to remove adjacent duplicated lines. Note that the use ofuniq, andsortallows to remove all duplicate lines. The flag-callows to count the number of times each word occursEx. Count the number of times a word occurs inside a file

How can I save the output of a pipe?
The shell lets us redirect the output of a sequence of piped commands:
cut -d , -f 2 seasonal/*.csv | grep -v Tooth > teeth-only.txtHow can I stop a running program?(
Ctrl+C)
If you decide that you don't want a program to keep running, you can typeCtrl+Cto end it.
Batch processing
Most shell commands will process many files at once. This chapter will show you how to make your own pipelines do that. Along the way, you will see how the shell uses variables to store information.
- How does the shell store information? Environment variable
Like other programs, the shell stores information in variables. Some of these, called environment variables, are available all the time. Environment variables' names are conventionally written in upper case, and a few of the more commonly-used ones are shown below. to get a complete list, you can type
to get a complete list, you can type setin the shell.
- How can I print a variable's value? (
echoand$)
A simpler way to find a variable's value is to use a command calledecho, which prints its arguments. Typingecho hello DataCamp!prints
hello DataCamp!If you try to use it to print a variable's value like this:
echo USERit will print the variable's name,
USER.To get the variable's value, you must put a dollar sign
$in front of it. Typingecho $USERprints
replThis is true everywhere: to get the value of a variable called
X, you must write$X. (This is so that the shell can tell whether you mean "a file named X" or "the value of a variable named X".) How else does the shell store information? shell variable
The other kind of variable is called a shell variable, which is like a local variable in a programming language.
To create a shell variable, you simply assign a value to a name:
training=seasonal/summer.csvwithout any spaces before or after the
=sign. Once you have done this, you can check the variable's value with:echo $trainingseasonal/summer.csv- How can I repeat a command many times? loops
Shell variables are also used in loops, which repeat commands many times. If we run this command:
for filetype in gif jpg png; do echo $filetype; doneit produces:
gif jpg pngNotice these things about the loop:

Notice that the body uses$filetypeto get the variable's value instead of justfiletype, just like it does with any other shell variable. Also notice where the semi-colons go: the first one comes between the list and the keyworddo, and the second comes between the body and the keyworddone. How can I repeat a command once for each file?
You can always type in the names of the files you want to process when writing the loop, but it's usually better to use wildcards. Try running this loop in the console:
for filename in seasonal/*.csv; do echo $filename; doneIt prints:
seasonal/autumn.csv seasonal/spring.csv seasonal/summer.csv seasonal/winter.csvbecause the shell expands
seasonal/*.csvto be a list of four filenames before it runs the loop.How can I record the names of a set of files?
People often set a variable using a wildcard expression to record a list of filenames. For example, if you define
datasetslike this:datasets=seasonal/*.csvyou can display the files' names later using:
for filename in $datasets; do echo $filename; doneThis saves typing and makes errors less likely.
- How can I run multiple commands in a single loop?
Printing filenames is useful for debugging, but the real purpose of loops is to do things with multiple files. This loop prints the second line of each data file:for file in seasonal/*.csv; do head -n 2 $file | tail -n 1; doneIt has the same structure as the other loops you have already seen: all that's different is that its body is a pipeline of two commands instead of a single command.
Why shouldn't I use spaces in filenames?
It's easy and sensible to give files multi-word names like
July 2017.csvwhen you are using a graphical file explorer. However, this causes problems when you are working in the shell. For example, suppose you wanted to renameJuly 2017.csvto be2017 July data.csv. You cannot type:mv July 2017.csv 2017 July data.csvbecause it looks to the shell as though you are trying to move four files called
July,2017.csv,2017, andJuly(again) into a directory calleddata.csv. Instead, you have to quote the files' names so that the shell treats each one as a single parameterHow can I do many things in a single loop?
The loops you have seen so far all have a single command or pipeline in their body, but a loop can contain any number of commands. To tell the shell where one ends and the next begins, you must separate them with semi-colons:
for f in seasonal/*.csv; do echo $f; head -n 2 $f | tail -n 1; doneseasonal/autumn.csv2017-01-05,canineseasonal/spring.csv2017-01-25,wisdomseasonal/summer.csv2017-01-11,canineseasonal/winter.csv2017-01-03,bicuspid
Creating new tools
History lets you repeat things with just a few keystrokes, and pipes let you combine existing commands to create new ones. In this chapter, you will see how to go one step further and create new commands of your own.
- How can I edit a file?
Unix has a bewildering variety of text editors. For this course, we will use a simple one called Nano. If you typenano filename, it will openfilenamefor editing (or create it if it doesn't already exist). You can move around with the arrow keys, delete characters using backspace, and do other operations with control-key combinations:Ctrl+K: delete a line.Ctrl+U: un-delete a line.Ctrl+O: save the file ('O' stands for 'output').Ctrl+X: exit the editor.
- How can I record what I just did?
When you are doing a complex analysis, you will often want to keep a record of the commands you used. You can do this with the tools you have already seen.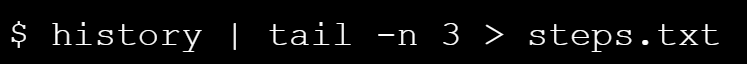
- How can I save commands to re-run later?
Usenano dates.shto create a file calleddates.shthat contains this command:cut -d , -f 1 seasonal/*.csvto extract the first column from all of the CSV files inseasonal.
Then, just run it by typingbash dates.sh
- How can I re-use pipes?
A file full of shell commands is called a *shell script, or sometimes just a "script" for short. Scripts don't have to have names ending in.sh, but this lesson will use that convention to help you keep track of which files are scripts.Scripts can also contain pipes. For example, if
all-dates.shcontains this line:cut -d , -f 1 seasonal/*.csv | grep -v Date | sort | uniqthen:
bash all-dates.sh > dates.outwill extract the unique dates from the seasonal data files and save them in
dates.out. How can I pass filenames to scripts? (
$@)A script that processes specific files is useful as a record of what you did, but one that allows you to process any files you want is more useful. To support this, you can use the special expression
$@(dollar sign immediately followed by at-sign) to mean "all of the command-line parameters given to the script". For example, ifunique-lines.shcontains this:sort $@ | uniqthen when you run:
bash unique-lines.sh seasonal/summer.csvthe shell replaces
$@withseasonal/summer.csvand processes one file. If you run this:bash unique-lines.sh seasonal/summer.csv seasonal/autumn.csvit processes two data files, and so on.
How can I process specific amount of arguments? (
$1,$2, ...)As well as
$@, the shell lets you use$1,$2, and so on to refer to specific command-line parameters. You can use this to write commands that feel simpler or more natural than the shell's. For example, you can create a script calledcolumn.shthat selects a single column from a CSV file when the user provides the filename as the first parameter and the column as the second:cut -d , -f $2 $1and then run it using:
bash column.sh seasonal/autumn.csv 1Notice how the script uses the two parameters in reverse order.
How can one shell script do many things?
Our shells scripts so far have had a single command or pipe, but a script can contain many lines of commands. For example, you can create one that tells you how many records are in the shortest and longest of your data files, i.e., the range of your datasets' lengths.
Note that in Nano, "copy and paste" is achieved by navigating to the line you want to copy, pressing
CTRL+Kto cut the line, thenCTRL+Utwice to paste two copies of it.Ex. Obtaining the range of our datasets's length. The script is
 And the next command is
And the next command is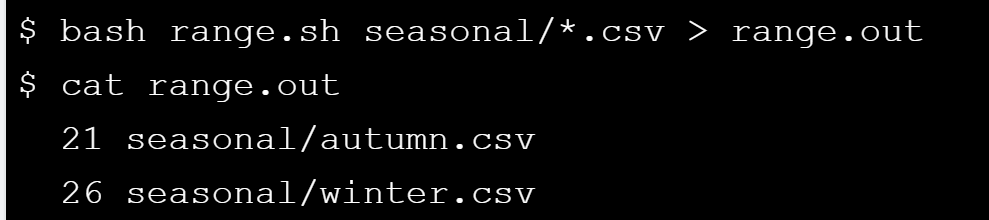
How can I write loops in a shell script?
Shell scripts can also contain loops. You can write them using semi-colons, or split them across lines without semi-colons to make them more readable:
# Print the first and last data records of each file.for filename in $@dohead -n 2 $filename | tail -n 1tail -n 1 $filenamedoneThe first line of this script is a comment to tell readers what the script does. Comments start with the
#character and run to the end of the line.s



