Introduction to Data Mining
Brought together by meeting certain challenges, researchers from different disciplines began to focus on developing efficient and scalable tools that could handle diverse types of data. This work culminated in the field of data mining.
- Motivating Challenges
- Scalability. Capability of a system, network, or process to handle a growing amount of work
- High Dimensionality.
- Heterogeneus and Complex Data.
- Data Ownership and Distribution. Sometimes, the data needed for an analysis is not stored in one location or owned by one organization. Thus we need distributed data mining techniques.
- Non-traditional Analysis. The traditional statistical approach is based on a hypothesis-testing paradigm but this process is extremely labor-intensive.
Data Mining adopts ideas from many areas such as Statistics, AI, Pattern Recognition, ML, Database Systems, Parallel computing, etc.
- Data Mining Tasks
- Predictive tasks. To predict the value of a particular attribute based on the values of other attributes.
- Descriptive tasks. To derive patterns (correlations, trends, clusters, trajectories, and anomalies) that summarize the underlying relationships in data.
Four of the core data mining tasks are: Cluster Analysis, Predictive Modelling, Anomaly Detection, and Association Analysis:
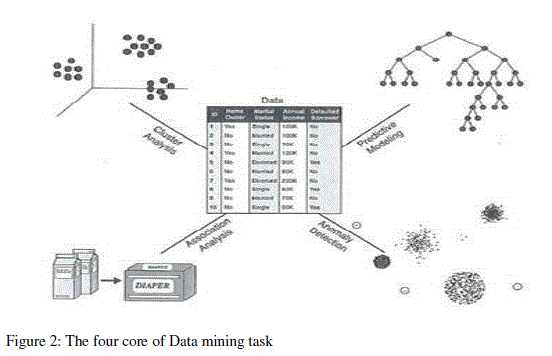
- Predictive Modelling. Refers to the task of builiding a model for the target variable as a function of the explanatory variables (classification o r regression depending on the target variable to be discrete or continuos, respectively)
- Association Analysis. Is ised to discover patterns that describe strongly associated features in the data. The discovered patterns are typically represented in the form of implication rules. The search space has exponential size, so its goal is to extract the most interesting patterns in an efficient manner.
- Cluster Analysis. Seeks to find groups of closely related observations so that observations of the same cluster are more similiar to each other than observarions to other clusters. Ex. Similarities between articles through the words used.
- Anomaly Detection. Identifies observations whose characteristics are significantly different from the rest of the data (anomalies/outliers). Ex. Detection of fraud, unusual patterns of disease, ecosystem disturbances, etc.
Data
Here we discuss several data-related issues that are important for successful data mining: Type of data, Quality of data, Preprocessing Steps to make the Data Suitable for Data Mining, and Analyzin Data in Terms of its relationships.
- The Type of Data. Type of data determines which tools and techniques can be used to analyze the data; often we need to accommodate new apllication areas and their new types of data. A data set can often be viewed as a collection of data objects (observations) that are described by a number of attributes (variables).
- Attributes and Measurement. We describe data by considering what types of attributes are used to describe data objects.
- Attribute. Is a property or characteristic of an object that may vary , either from one object to another or from one time to another. To analyze the characteristics of an object we assign numbers o symbols to them.
- Measurement scale. Is a function that associates a numerical or symbolic value with an attribute of an object.
- Obs. The values used to represent an attribute may have properties that are not properties of the attribute itself, and viceversa.
- Different types of attributes. There are two main ways to define the types; depending on the properties and operations that the attributes haver, or in terms of their permissible transformations
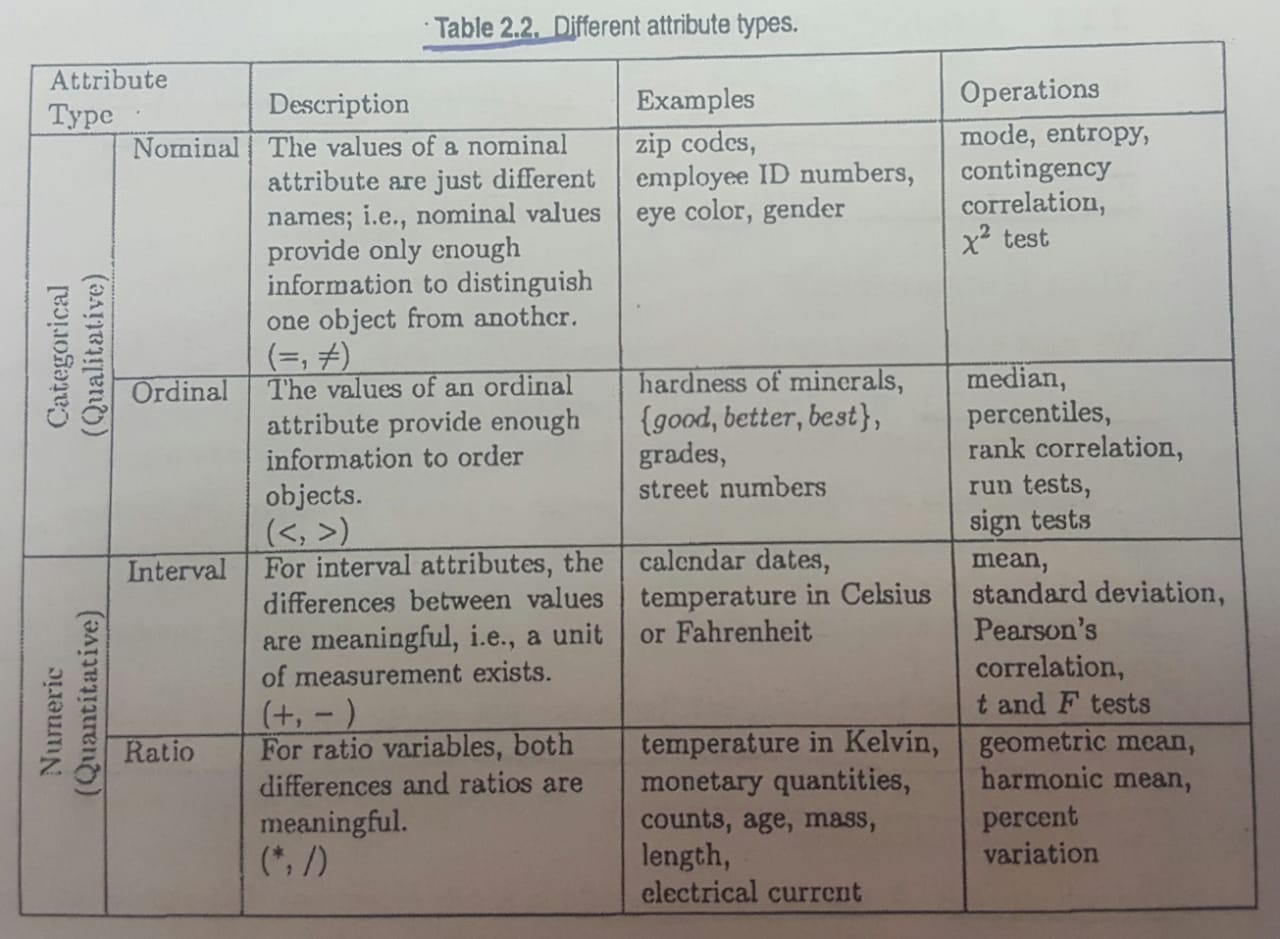
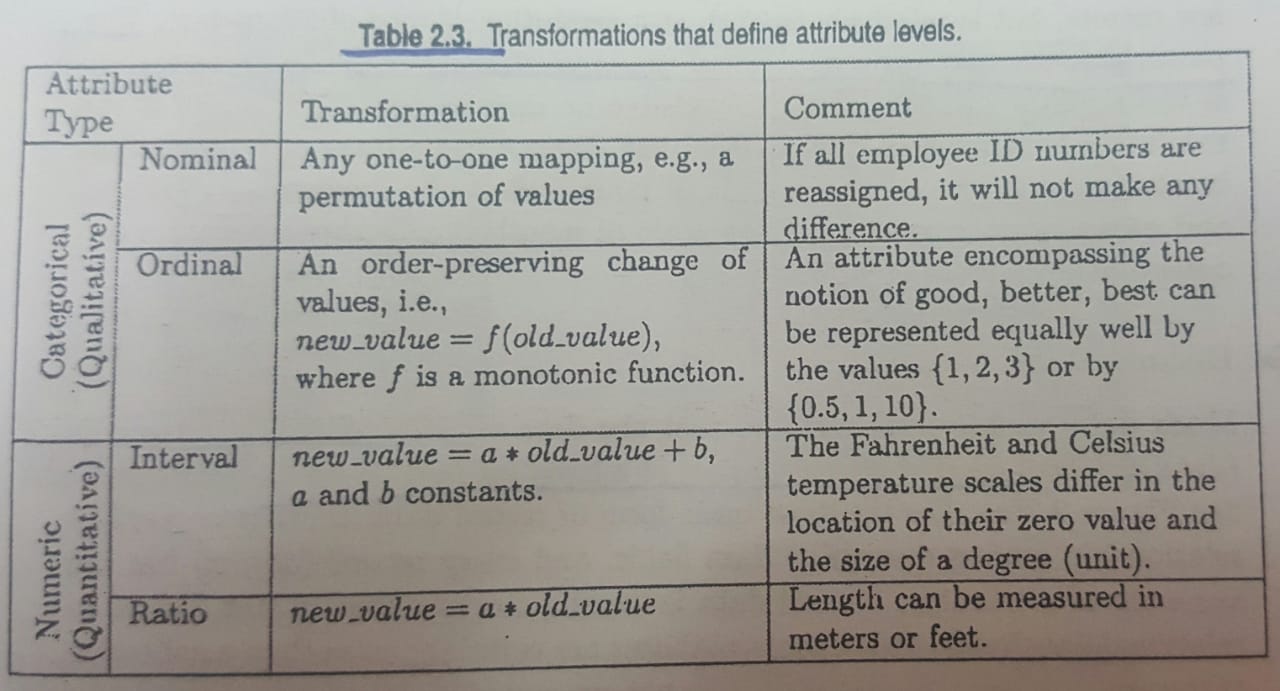
- We can also describe attributes by the numer of values. Such as discrete or continuous.
- Asymmetric Attributes. Only presence is regarded as important; we ignore the presence of zeroes for example if the imply absence of something.
- Attribute. Is a property or characteristic of an object that may vary , either from one object to another or from one time to another. To analyze the characteristics of an object we assign numbers o symbols to them.
- Types of Data Sets. We first look at general characteristics of data sets: Dimensionality (number of attributes; an important part of preprocessing data is dimensionality reduction), Sparsity (when we have to ignore most of the values for being zeroes, so only non-zero values need to be stored and manipulated), Resolution (it is frquently possible to obtain data at different levels of resolution, and their properties are different at different resolutions). Now we describe some of the most common types of data sets:
- Record Data. A collection of records, each of which consists of a fixed set od data fields (attributes).
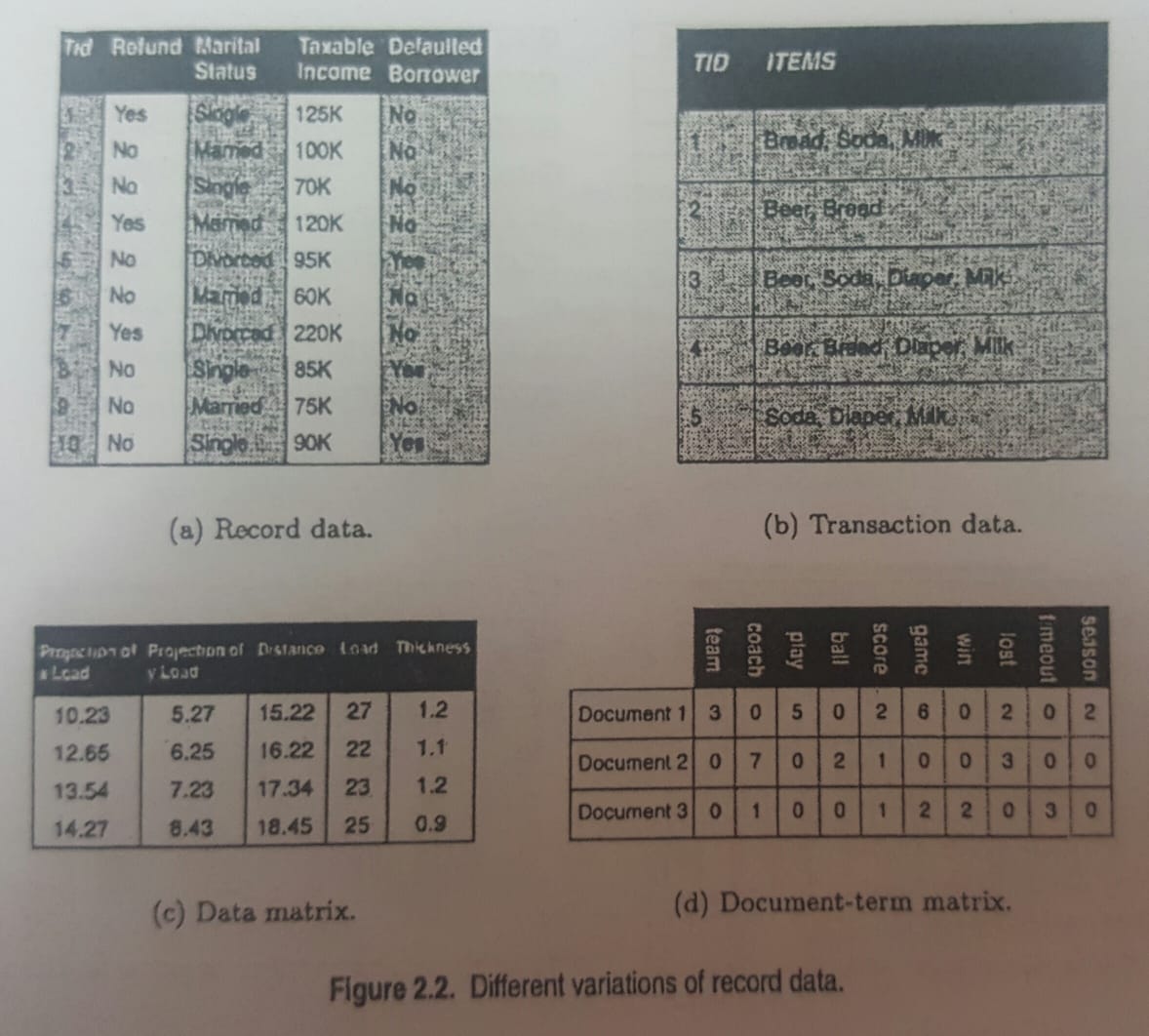
- Graph-Based Data. We consider two specific cases: (1) the graph captures relationships among data objects and (2) the data objects themselves are represented as graphs.
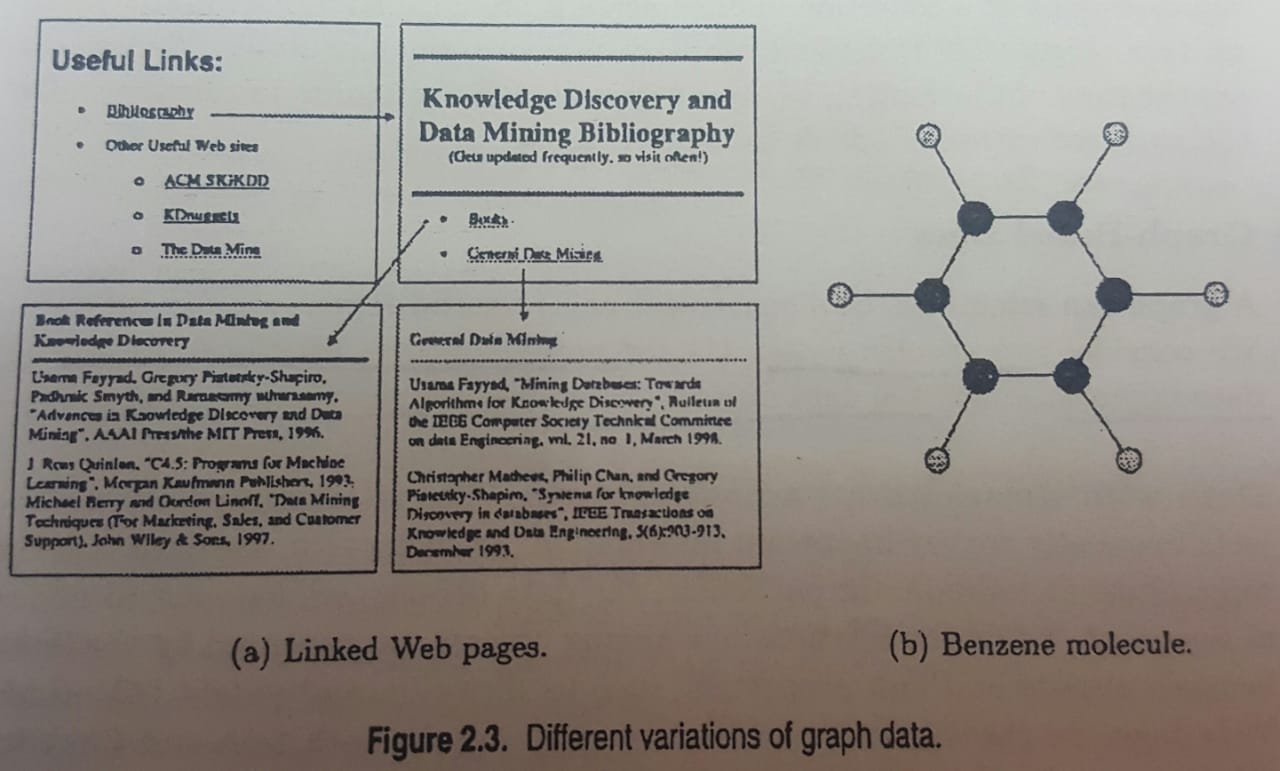
- Ordered Data. The attributes have relationships that involve order in time or space. Sequential data (extension of record data where each record has an associated time), Sequence data (sequence of individual entities), Time Series data (each record is a time series, ie a series of measurements taken over time), Spatial data (objects with spatial attributes).

- Remark. Most data mining algorithms are designed for record data or its variations such as transaction data and data matrices. Record-oriented techniques can be applied to non-record data by extracting features from data objects and using these features to create a record correspoding to each object; nevertheless sometimes it won't capture all the information in the data.
- Record Data. A collection of records, each of which consists of a fixed set od data fields (attributes).
- Attributes and Measurement. We describe data by considering what types of attributes are used to describe data objects.
Comments



