Joining Data in R with dplyr
Benefits of dplyr join functions: the dplyr join functions always preserve row order, have intuitive syntaz and can be applied to databses, spark, etc (this way you can perform Big Data tasks).
Mutating joins
This chapter will explain the various ways you can join datasets together and what happens when you do. The dplyr join functions always preserve row order, have intuitive syntaz and can be applied to databses, spark, etc. Left join and right join are half of a class of joins called mutating joins.
- Keys.
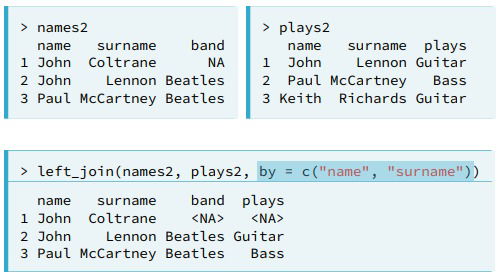
The job of the join is to find rows that match and to make sure that they are placed into the same row in the final datatable. A key is a column or a combinations of columns that occurs in each of the tables that you want to join, dplyr matches the rows that have the same values of the key. You will have a primary key, for the first table it is better when each key here is distinct (for these maybe you should use two variabels as primary key); and a foreign key, for the second table where there could be duplicates. - left_join(). You can use it whenever you want to augment a dataframe with information from another dataframe. You may use it with one or multiple variables as a key.
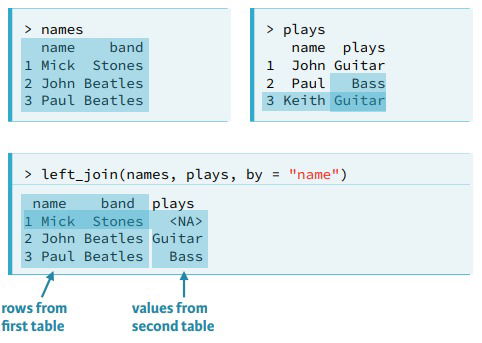
- right_join(). It works exactly the same as left_join() but reversing the order of the tables.
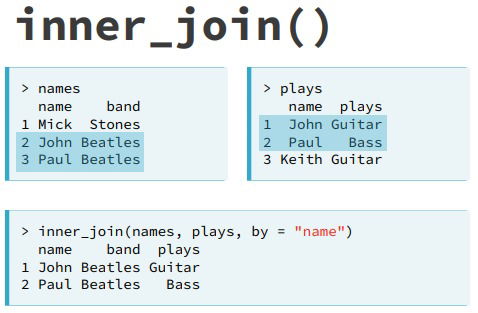
- inner_join(). It only keeps observations which appear in both tables.
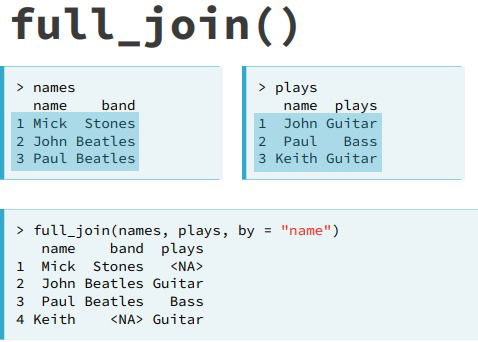
- full_join(). It keeps all of the observations from both tables.

- Obs.
- Use setequal() to see whether or not to dataframes are equal.
- All of the joining functions follow the same syntax

- Pipe operator.
Filtering joins and set operations
- semi_join() Provide a concise way to filter data from the first dataset based on information in a second dataset.
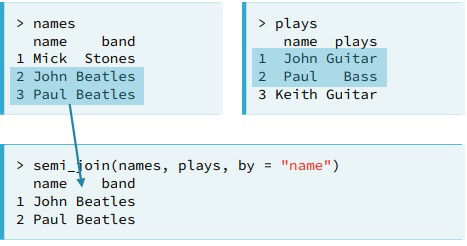
- Exploring. Semi-joins provide a useful way to explore the connections between multiple tables of data.
For example, you can use a semi-join to determine the number of albums in the
albumsdataset that were made by a band in thebandsdataset.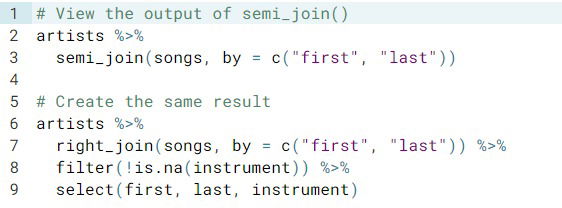
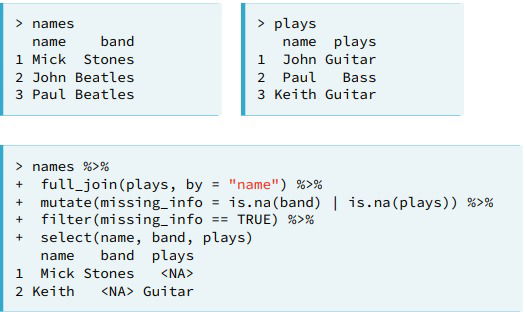
anti_join(). You filter data from your first dataset so that it does not match to a second dataset. Provide a useful way to reason about how a mutating join will work befor you apply the join. (If you apply a left_join() you can use it to see which rows will contain a missing value).

anti_join() can help you zero-in on rows that have capitalization or spelling errors in the keys.
Set Operations. These are used when we have two datasets with the same variables and we want to obtain the union, intersection, difference.
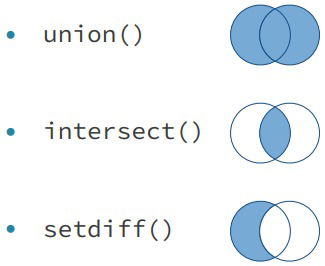
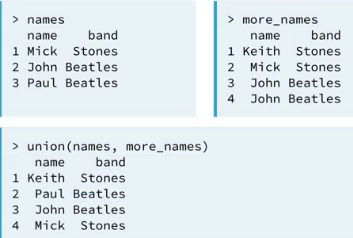
union()
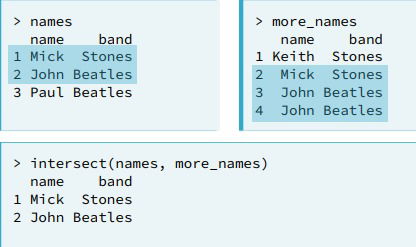
intersect()
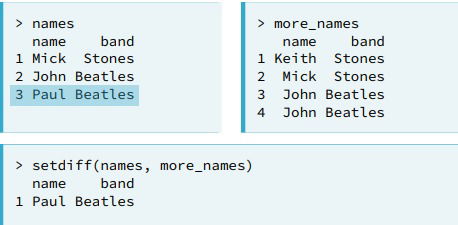
setdiff()
Comparing tables.
setequal(). Compares the set of rows
identical(). Compares the set of rows and the order ot these.
Assembling Data
- Creating data frames
- bind_rows(). Will bind the rows from 2+ data frames
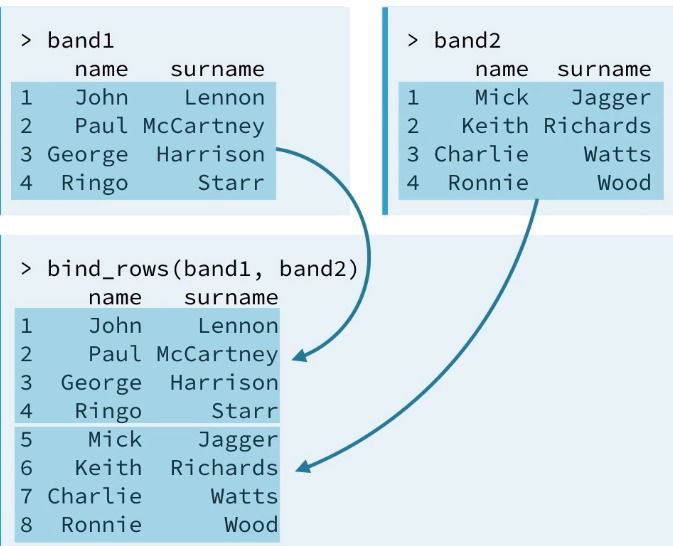
- It has a special feature over cbind(), you can add a column to specify from which data frame the observation comes.
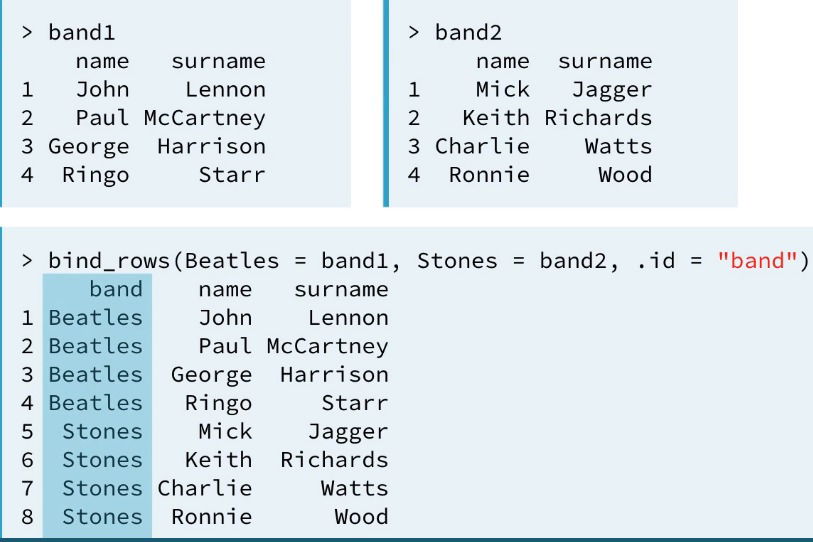
- Ex.

- It has a special feature over cbind(), you can add a column to specify from which data frame the observation comes.
- bind_cols(). Will bind the columns from 2+data frames.

- Characteristics from bind_rows() ad bind_cols()

- data_frame().


- You can also use defined variables inside it for other variable creation.

- You can also use defined variables inside it for other variable creation.
- as_data_frame(). It is exactly the same as as.data.frame()
- bind_rows(). Will bind the rows from 2+ data frames
- Coercion. The most complicate coercion rules are the ones involving factors.

Advanced Joining
- What can go wrong?
- Missing key values. There's not much you can do with this happen, unless you imput a value you could delete the row.
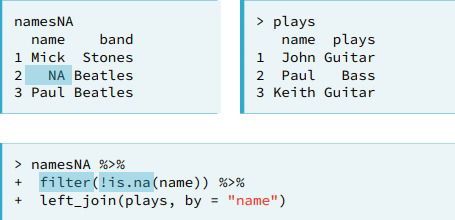
- Remark. When you join two datasets together that have missing values in the key columns the join will act as if these values are equal. To avoid this, remove NA's from key before joining.
- Missing key column. You will always need a key column to join datasets. Sometimes the rownames is the key column you need, to add this as a column use rownames_to_colum().
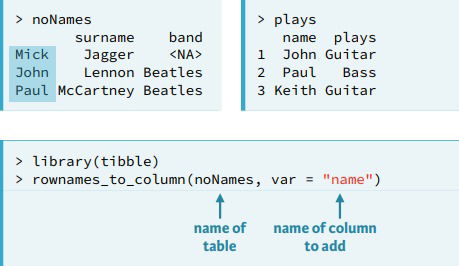
- Duplicate key values. This could be an indicator to add annother column to the key, but also could be part of the dataitself.
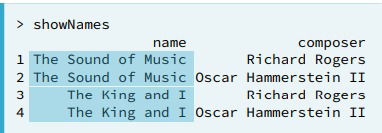
- Missing key values. There's not much you can do with this happen, unless you imput a value you could delete the row.
- Defining the keys
- Obs. The join functions in dplyr will automatically look for matching names of variables in both tables if "by=" is not specified.
- Mismatched key names. If your tables have distinct names for the key you want to use.
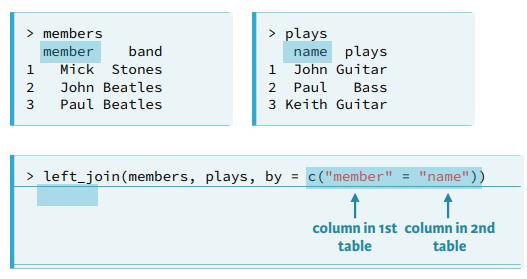
- Conflicting names. When your tables have columns with the same name dplyr adds the suffix .x and .y but you can specify them.
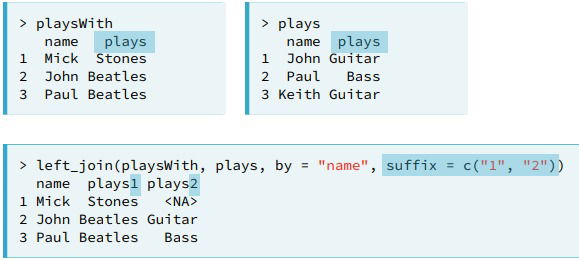
rename(data, new_name = old_name)renamesold_nametonew_nameindata
- Joning multiple tables. For this purpose, the purrr package is used, its job is to take R functions and apply them to data in efficient ways.
- reduce(). The job of
reduce()is to apply a function in an iterative fashion to many datasets. This function will work for any function that can accept elements from the list as its first two arguments. You can pass arguments required by the function as shown with "by='name'" in the following example.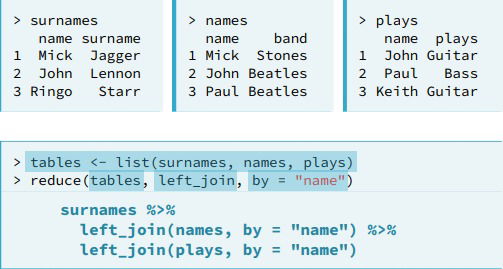
- reduce(). The job of
- Other implementations (R built in and SQL)
- merge(). You can use it to do any mutating join

- SQL
- Commands

- Database connections

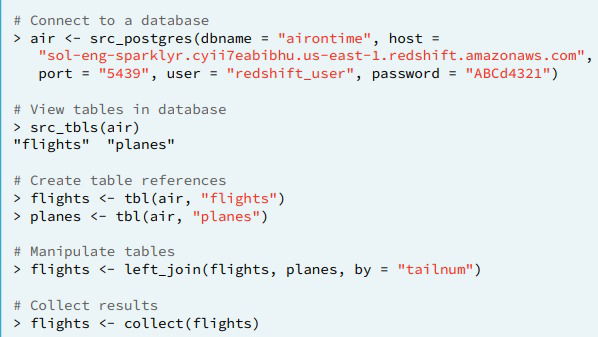
- Commands
- merge(). You can use it to do any mutating join
Case Study
- Common keys. Identify common keys among multiple data frames
- s
- Useful functions.
- distinct(). Receives a dataframe and returns a dataframe without repeated observations.
- You can also find unique rows for specific columns using the following syntax:
tbl %>% # Find unique rows of columns a,b, and c distinct(a, b, c)
- You can also find unique rows for specific columns using the following syntax:
- count(). Counts the number of rows. If you specify the 'vars= ' argument it groups by such variables and return the count for each group.
- distinct(). Receives a dataframe and returns a dataframe without repeated observations.
- Can you determine how many games each of these unsalaried players played?
- s



